83 min to read
Core Java™, Volume Ⅱ-Advanced Features
(Eleventh Edition) Book Notes

- 第1章 Java 8的流库
- 第2章 输入与输出
- 第3章 XML
- 第4章 网络
- 第5章 数据库编程
- 第6章 日期和时间API
- 第7章 国际化
- 第8章 脚本、编译与注解处理
- 第9章 Java平台模块系统
- 第10章 安全
- 第11章 高级Swing和图形化编程
- 第12章 本地方法
第1章 Java 8的流库
从迭代到流的操作
流的创建
filter、map和flatMap方法
并行流
简单约简
- 通过使用流,可以说明想要完成什么任务,而不是说明如何去实现它。
1.1 从迭代到流的操作
- 流表面上看起来和集合很类似,都可以让我们转换和获取数据。但是,它们之间存在着显著的差异:
- 流并不存储元素。这些元素可能存储在底层的集合中,或者按需生成。
- 流的操作不会修改其数据源。
- 流的操作是尽可能惰性执行的。这意味着直至需要其结果时,操作才会执行。
// 计数:字符串列表words中所有长度大于12的单词
long count = 0;
// 1. 常规方式
for (String w : words) {
if (w.length() > 12)
count++;
}
// 2. 流
count = words.stream().filter(w -> w.length() > 5).count();
// 3. 并行流
count = words.parallelStream().filter(w -> w.length() > 5).count();
1.2 流的创建
- Collection接口的stream方法可以将任何集合转换为一个流。而数组则使用静态的Stream.of方法。
Stream<String> words = Stream.of(contents.split("\\PL+")); // split("\\PL+") 以非字母(\\PL+)为分隔
// of 方法句有可变长参数
Stream<String> words = Stream.of("gently", "down", "the", "stream");
- Array.stream(array,from,to) 可以用数组中的一部分(form到to)来创建一个流。
- 静态的Stream.empty方法可以创建不包含任何元素的流。
Stream<String> silence = Stream.empty();
// Generic type <String> is inferred; same as Stream.<String>empty()
- 一些流相关的方法
// 获得一个常量值的流
Stream<String> echos = Stream.generate(() -> "Echo");
// 获取一个随机数的流
Stream<Double> randoms = Stream.generate(Math::random);
/** iterate方法
* 会接受一个“种子”值,
* 以及一个函数,
* 并且会反复地将该函数应用到之前的结果上。
* 下例会生成一个 0 1 2 3...这样的序列。
*/
Stream<BigInteger> integers
= Stream.iterate(BigInteger.ZERO, n -> n.add(BigInteger.ONE)
/** 生成一个有限序列
* 添加一个谓词描述迭代应该何时结束。
*/
var limit = new BigInteger("1000000");
Stream<BigInteger> integers
= Stream.iterate(BigInteger.ZERO,
n -> n.compareTo(limit) < 0,
n -> n.add(BigInteger.ONE)
/** Pattern类的splitAsStream方法
* 按照某个正则表达式来分割一个CharSequence对象。
*/
Stream<String> words = Pattern.compile("\\PL+").splitAsStream(contents);
/** Scanner.tokens方法
* 会产生一个扫描器的符号流。
*/
Stream<String> words = new Scanner(contents).tokens();
/** 静态Files.lines方法
* 会返回一个包含了文件中所有行的Stream。
try (Stream<String> lines = Files.lines(path)) {
Process lines
}
/** 若持有的Iterable对象不是集合,
* 则可以通过下面的方法将其转换为一个流。
*/
StreamSupport.stream(iterable.spliterator(), false);
/** 若持有的是Iterator对象,
* 得到一个由它结果构成的流。
*/
StreamSupport.stream(Spliterators.spliteratorUnknownSize(
iterator, Spliterator.ORDERED), false);
1.3 filter、map和flatMap方法
- filter方法会产生一个新流,它的元素与某种条件相匹配。
// 将一个字符串流转换为只包含长单词(长度大于12)的新流
List<String> words = ...;
Stream<String> longWords = words.stream().filter(w -> w.length() > 12);
- map方法传递执行转换函数。
// 函数 将所有单词转换成小写
Stream<String> lowercaseWords = words.stream().map(String::toLowerCase);
// lambda表达式 新流中包含所有单词的首字母
Stream<String> lowercaseWords = words.stream().map(s -> s.substring(0,1));
- flatMap方法。
public static Stream<String> codePoints(String s) {
var result = new ArrayList<String>();
int i= 0;
while (i < s.length()) {
int j = s.offsetByCodePoints(i, 1);
result.add(s.substring(i, j));
i = j;
}
return result.stream();
}
/** codePoints("boat")的返回值是流["b", "o", "a", "t"]
* 将codePoints方法映射到一个字符串流上
*/
Stream<Stream<String>> result = words.stream().map(w -> codePoints(w));
/** 上述代码会得到一个包含流的流
* [...["y", "o", "u", "r"],["b", "o", "a", "t"],...]
* 为了将其摊平为单个流
* [..."y", "o", "u", "r", "b", "o", "a", "t",...]
* 使用flatMap方法而不是map方法
*/
Stream<String> flatResult = words.stream().flatMap(w -> codePoints(w));
1.4 抽取子流和组合流
- 调用stream.limit(n)会返回一个新的流,它在n个元素之后结束(若原来的流比n短,则在该流结束时结束)。
// 产生一个包含100个随机数的流
Stream<Double> randoms = Stream.generate(Math::random).limit(100);
- 调用stream.skip(n)正好相反,它会丢弃(跳过)前n个元素。
// 跳过第一个元素
Stream<String> words = Stream.of(contents.split("\\PL+")).skip(1);
- stream.takeWhile(predicate)调用会在谓词为真时获取流中的所有元素,然后停止。
/** 上文codePoints方法将字符串分割为字符,然后收集所有的数字元素。
* takeWhile方法可以实现此目标。
*/
Stream<String> initialDigits = codePoints(str).takeWhile(s -> "0123456789".contains(s));
- dropWhile方法正好相反,它会在条件为真时丢弃元素,并产生一个由第一个使该条件为假的字符开始的所有元素构成的流。
Stream<String> withoutInitialWhiteSpace
= codePoints(str).dropWhile(s -> s.trim().length() == 0);
- Stream类的静态concat方法可以将两个流连接起来
Stream<String> combined = Stream.concat(codePoints("Hello"), codePoints("World");
// Yields the stream ["H", "e", "l", "l", "o", "W", "o", "r", "l", "d"]
1.5 其他流的转换
- distinct方法会返回一个流,它的元素是从原有流中产生的,即原来的元素按照同样的顺序剔除重复元素后产生的。
Stream<String> uniqueWords = Stream.of("merrily", "merrily", "merrily", "gently").distinct();
// only one "merrily" is retained
- 流的排序有多种sorted方法的变体可用。其中一种用于操作Comparable元素的流,而另一种可以接受一个Comparator。
// 使最长的字符串排在最前面
Stream<String> longestFirst = words.stream().sorted(Comparator.comparing(String::length).reversed());
与所有流转换一样,sorted方法会产生一个新的流,它的元素是原有流中按照顺序排列的元素。
- peek方法会产生另一个流,它的元素与原来流中的元素相同,但是在每次获取一个元素时,都会调用一个函数。
Object[] powers
= Stream.iterate(1.0, p -> p * 2).peek(e -> System.out.println("Fetching " + e)).limit(20).toArray();
1.6 简单约简
- 约简是一种终结操作(terminal operation),它们会将流约简为可以在程序中使用的非流值。
- 简单约简:
/** 1. count方法
* 返回流中的元素的数量。
*/
Stream<String> example = Stream.of("merrily", "merrily", "merrily", "gently");
System.out.println(example.count()); // print 4
/** 2. max和min方法
* 返回流中的元素的最大值和最小值。
*/
Optional<String> largest = words.max(String::compareToIgnoreCase);
System.out.println("largest: " + largest.orElse(""));
/** 3. findFirst方法
* 返回非空集合中的第一个值。
* 与filter组合使用时很有用。
* 找到第一个以字母Q开头的单词。
*/
Optional<String> startsWithQ = words.filter(s -> startsWith("Q")).findFirst();
/** 4. findAny方法
*/
Optional<String> startsWithQ = words.filter(s -> startsWith("Q")).findAny();
/** 5. anyMatch方法
* 检测是否存在匹配。
* 接受一个断言引元,
* 因此不需要使用filter。
*/
boolean aWordStartsWithQ = words.parallel().anyMatch(s -> startsWith("Q"));
/** 6. allMatch和noneMatch方法
* 分别在所有元素
* 和没有任何元素匹配谓词
* 的情况下返回true。
*/
1.7 Optional类型
- Optional
对象是一种包装器对象,要么包装了类型T的对象,要么没有包装任何对象。
1.7.1 获取Optional值
- 有效地使用Optional的关键:它在值不存在的情况下会产生一个可替代物,而只有在值存在的情况下才会使用这个值。
// 在没有任何匹配时,使用某种默认值,可能是空字符串。
String result = optionalString.orElse("");
// The wrapped string, or "" if none
// 调用代码计算默认值
String result = optionalString.orElseGet(() -> System.getProperty("myapp.default"));
// The function is only called when needed
// 或者在没有任何值时抛出异常
String result = optionalString.orElseThrow(IllegalStateException::new);
// Supply a method that yield an exception object
1.7.2 消费Optional值
- ifPresent方法会接受一个函数
/** 如果可选值存在,
* 那么它会被传递给该函数。
* 否则,不会发生任何事情。
*/
optionalValue.ifPresent(v -> Process v);
/** 例如,如果在该值存在的情况下,
* 要将其添加到某个集中,
* 那么可以调用:
*/
optionalValue.ifPresent(v -> results.add(v)); // or optionalValue.ifPresent(results::add);
/** ifPresentOrElse方法
* 可选值存在时执行一种动作,
* 可选值不存在时执行另一种动作。
*/
optionalValue.ifPresentOrElse(v -> System.out.println("Found " + v), () -> logger.warning("No match"));
1.7.3 管道化Optional值
// 使用map方法来转换Optional内部的值。
Optional<String> transformed = optionalString.map(String::toUpperCase);
// 如果optionalString为空,则transformed也为空
// 将一个结果添加到列表中
optionalValue.map(results::add);
// 如果optionalValue为空,则什么也不会发生
1.7.4 不适合使用Optional值的方式
- Optional类型正确用法的提示:
- Optional类型的变量永远都不应该为null。
- 不要使用Optional类型的域。因为其代价是额外多出来一个对象。在类的内部,使用null表示缺失的域更易于操作。
- 不要在集合中放置Optional对象,并且不要将它们用作map的键。应该直接收集其中的值。
1.7.5 创建Optional值
- 若想要编写方法来创建Optional对象,可以使用Optional.of(result)和Optional.empty()。
public static Optional<Double> inverse(Double x) {
return x == 0 ? Optional.empty() : Optional.of(1/x);
}
- ofNullable方法被用来作为可能出现的null值和可选值之间的桥梁。Optional.ofNullable(obj)会在obj不为null的情况下返回Optional.of(obj),否则会返回Optional.empty()。
1.7.6 用flatMap构建Optional值的函数
/** f方法可以产生Optional<T>对象,
* 目标类型T具有一个可以产生Optional<U>对象的方法g。
* 则可通过s.f().g()将它们组合起来。
* 但是这种组合无法工作,
* 因为s.f()的类型为Optional<T>,而不是T。
* 故需要使用flatMap方法。
*/
Optional<T> result = s.f().flatMap(T::g);
// 若s.f()的值存在,那么g就可以应用到它上面。否则,就会返回一个空Optional<U>。
1.7.7 将Optional转换为流
- stream方法会将一个Optional
对象转换为一个具有0个或1个元素的Stream 对象。
/** 有一个用户ID流和
* 方法Optional<User> lookup(String id)
*/
Stream<String> ids = ...;
Stream<User> users = ids.map(Users::lookup).filter(Optional::isPresent).map(Optional::get);
/** 过滤掉无效ID,
* 然后将get方法应用于剩余的ID。
* 但是要慎用isPresent和get方法,
* 故修改代码。
*/
Stream<User> users = ids.map(Users::lookup).flatMap(Optional::stream);
1.8 收集结果
- forEach方法,将函数运用于每个元素。
stream.forEach(System.out::println);
在并行流上,forEach方法会以任意顺序遍历各个元素。forEachOrdered方法可以按照流中的顺序来处理,但该方法会丧失并行处理的部分甚至全部优势。
- 表达式stream.toArray()会返回一个Object[]数组。将其传递到数组构造器中,能够让数组拥有正确的类型。
String[] result = stream.toArray(String[]::new);
// stream.toArray() has type Object[]
- 收集器是一种收集众多元素并产生单一结果的对象,Collectors类提供了大量用于生成常见收集器的工厂方法。
// 将流的元素收集到一个列表中
List<String> result = stream.collect(Collectors.toList());
// 将流的元素收集到一个集中
Set<String> result = stream.collect(Collectors.toSet());
// 控制获得的集的种类
TreeSet<String> result = stream.collect(Collectors.toCollection(TreeSet::new));
// 通过连接操作来收集流中所有字符串
String result = stream.collect(Collectors.joining());
// 元素之间增加分隔符
String result = stream.collect(Collectors.joining(", "));
// 将流中非字符串对象转换为字符串
String result = stream.map(Object::toString).collect(Collectors.joining(", "));
1.9 收集到映射表中
- Collectors.toMap方法有两个函数引元,它们用来产生映射表的键和值。
/** 将一个流Stream<Person>的元素收集到映射表中,
* 以便后续通过ID来查找人员。
*/
Map<Integer, String> idToName = people.collect(Collectors.toMap(Person::getId, Person::getName));
// 通常情况下,值应该是实际的元素,因此第二个函数可以使用Function.identity()。
Map<Integer, String> idToPerson = people.collect(Collectors.toMap(Person::getId, Function.identity()));
1.10 群组和分区
- 将具有相同特性的值群聚成组是非常常见的,并且groupingBy方法直接就支持它。
Map<String, List<Locale>> countryToLocales = locales.collect(Collectors.groupingBy(Locale::getCountry));
/** 函数Locale::getCountry是群组的分类函数,
* 可以查找给定国家代码对应的所有地点。
*/
List<Locale> swissLocales = countryToLocales.get("CH");
// Yields locales de_CH, fr_CH, it_CH and maybe more
- 当分类函数是断言函数(即返回boolean值的函数)时,流的袁术可以分为两个列表:该函数返回true的元素和其他的元素。这种情况下,使用partitioningBy比使用groupingBy更高效。
// 将所有locale分成了使用英语和使用其他英语的两类
Map<Boolean, List<Locale>> englishAndOtherLocales
= locales.collect(Collectors.partitioningBy(l -> l.getLanguage.equals("en")));
List<Locale> englishLocales = englishAndOtherLocales.get(true);
1.11 下游收集器
- groupingBy方法会产生一个映射表,它的每个值都是一个列表。“下游处理器”能够以某种方式来处理这些列表。
Map<String, Set<Locale>> countryToLocaleSet = locales.collect(groupingBy(Locale::getCountry, toSet()));
- Java提供了多种可以将收集到的元素约简为数字的收集器。
/** 1. counting
*会产生收集到的元素的个数。
*/
Map<String, Long> countryToLocaleCounts = locales.collect(groupingBy(Locale::getCountry, counting()));
/** 2. summing(Int|Long|Double)
* 会接受一个函数作为引元,
* 将该函数应用到下游元素中,
* 并产生它们的和。
*/
Map<String, Integer> stateToCityPopulation
= cities.collect(groupingBy(City::getState, summingInt(City::getPopulation)));
/** 3. maxBy和minBy
* 会接受一个比较器,
* 并分别产生下游元素中的最大值和最小值。
*/
Map<String, Optional<City>> stateToLargestCity
= cities.collect(groupingBy(City::getState, maxBy(Comparator.comparing(City::getPopulation))));
// 可以产生每个州中最大的城市。
1.12 约简操作
- reduce方法是一种用于从流中计算某个值的通用机制,其简单的形式将接受一个二元函数,并从前两个元素开始持续应用它。
List<Integer> values = ...;
Optional<Integer> sum = values.stream().reduce((x, y) -> x + y);
/** reduce方法会计算v0+v1+v2+...,其中vi是流中的元素。
* 若流为空,则该方法会返回一个Optional。
*/
1.13 基本类型流
- 流库中具有专门的类型IntStream、LongStream和DoubleStream,用来直接存储基本类型值,而无须使用包装器。
- IntStream存储short、char、byte和boolean。
- DoubleStream存储float。
- 创建IntStream,需要调用IntStream.of和Arrays.stream方法:
IntStream stream = IntStream.of(1, 1, 2, 3, 5);
stream = Arrays.stream(values, from, to); // values is an int[] array
- 基本类型流上的方法与对象流上的方法类似。下面是主要的差异:
- toArray方法会返回基本类型数组。
- 产生可选结果的方法会返回一个OptionalInt、OptionalLong或OptionalDouble。这些类与Optional类类似,但是具有getAsInt、getAsLong和getAsDouble方法,而不是get方法。
- 具有分别返回总和、平均值、最大值和最小值的sum、average、max和min方法。对象流没有定义这些方法。
- summaryStatistics方法会产生一个类型为IntSummaryStatistics、LongSummaryStatistics或DoubleSummaryStatistics对象,它们可以同时报告流的总和、数量、平均值、最大值和最小值。
1.14 并行流
- Collection.parallelStream()方法从任何集合中获取一个并行流:
Stream<String> parallelWords = words.parallerStream();
- parallel方法可以将任意的顺序流转换为并行流:
Stream<String> parallelWords = Stream.of(wordArray).parallel();
- 不要指望通过将所有的流都转换为并行流就能加速操作,要牢记:
- 并行化会导致大量的开销,只有面对非常大的数据集才划算。
- 只有在底层的数据源可以被有效地分割为多个部分时,将流并行化才有意义。
- 并行流使用的线程池可能会因诸如文件I/O或网络访问这样的操作被阻塞而饿死。只有面对海量的内存数据和运算密集处理,并行流才会工作最佳。
第2章 输入与输出
输入/输出流
内存映射文件
读写二进制数据
文件锁机制
对象输入/输出流与序列化
正则表达式
操作文件
2.1 输入/输出流
- 在Java API中,可以从其中读入一个字节序列的对象称作输入流,而可以向其中写入一个字节序列的对象称作输出流。
- 抽象类InputStream和OutputStream构成了输入/输出(I/O)类层次结构的基础。
2.1.1 读写字节
- InputStream类有一个抽象方法:
abstract int read()
/** 该方法将读入一个字节,
* 并返回读入的字节,
* 或者在遇到输入源结尾时返回-1。
// 从Java 9开始,读取流中所有字节的方法
byte[] bytes = in.readAllBytes();
- OutputStream类有一个抽象方法:
// 向某个输出位置写出一个字节
abstract void write(int b)
// 一次性写出一个字节数组
byte[] values = ...;
out.write(values);
// transferTo方法可以将所有字节从一个输入流传递到输出流
in.transferTo(out);
- read和write方法在执行时都将阻塞,直至字节确实被读入或写出。
- 当完成对输入/输出流的读写时,应该通过调用close方法关闭它,这会释放掉十分有限的操作系统资源。而且,如果不关闭文件,那么写出字节的最后一个包可能永远也得不到传递,从而导致写文件失败。
2.1.2 完整的流家族
- Java拥有一个流家族,包含各种输入/输出流类型,其数量超过60个。
2.1.3 组合输入/输出流过滤器
- FileInputStream和FileInputStream可以提供附着在一个磁盘文件上的输入流和输出流,而只需要向其构造器提供文件的完整路径名。
var fin = new FileInputStream("employee.dat");
// 这行代码可以查看用户目录下名为“employee.dat”的文件。
由于反斜杠字符在Java字符串中是转义字符,因此要确保在Windows风格的路径名中使用\\。
- 某些输入流可以从文件和其他更外部的位置上获取字节,而其他输入流可以将字节组装到更有用的数据类型中。例如,为了从文件中读入数字,首先要创建一个FileInputStream,然后将其传递给DataInputStream的构造器:
var fin = new FileInputStream("employee.dat");
var din = new DataInputStream(fin);
double x = din.readDouble();
2.1.4 文本读入与输出
- 在保存数据时,可以选择二进制格式或文本格式。例如,整数1234存储成二进制数时候,会被写为由字节 00 00 04 D2构成的序列(16进制表示法),而存储成文本格式时,则被存成了字符串“1234”。
- 文本格式:人类可阅读。
- 二进制格式:效率高。
2.1.5 如何写出文本输出
- 文本输出,可以使用PrintWriter。
var out = new PrintWriter("employee.txt", StandardCharsets.UTF_8);
String name = "Lam";
double salary = 75000;
out.print(name);
out.print(' ');
out.println(salary);
// employee.txt文件中有 Lam 75000.0
2.1.6 如何读入文本输入
// 最简单 Scanner类
Scanner in = new Scanner(Path.of("inputfile.txt"),StandardCharsets.UTF_8);
String s1=in.nextLine();
// 将短小的文本文件读入到一个字符串中
var content = (Files.read String path, charset);
// 一行一行地读入
List<String> lines = Files.readAllLines(path, charset);
// 较大文件,将行惰性处理为一个Stream<String>对象
try (Stream<String> lines = Files.lines(path, charset)) {
...
}
// 使用扫描器来读入符号(token),即由分隔符分隔的字符串,默认的分隔符是空白字符
Scanner in = ...;
in.useDelimiter("\\PL+"); // 将分隔符修改为任意的正则表达式
// 调用next方法可以产生下一个符号
while (in.hasNext()) {
String word = in.next();
...
}
// 获取一个包含所有符号的流
Stream<String> words = in.tokens();
- 在早期的Java版本中,处理文本输入的唯一方式就是通过BufferedReader类。它的readLine会产生一行文本,或者在无法获得更多的输入时返回null。
InputStream inputStream = ...;
try (var in = new BufferedReader(new InputStreamReader(inputStream, charset))) {
String line;
while ((line = in.readLine()) != null) {
do something with line
}
}
2.1.7 以文本格式存储对象
- 输出
public static void writeEmployee(PrintWriter out, Employee e) {
out.println(e.getName() + "|" + e.getSalary + "|" + e.getHireDay());
}
//在调用该方法之后 切记使用out.close()关闭文件
// 调用该方法打印到文本文件中
Harry Hacker|35500|1989-10-01
Carl Cracker|75000|1987-12-15
Tony Tester|38000|1990-03-15
- 输入
/** 每次读入一行,
* 然后分离所有字段。
* 用扫描器来读入每一行,
* 然后用String.split方法将这一行断开成一组标记。
*/
public static Employee readEmployee(Scanner in) {
String line = in.nextLine();
String[] tokens = line.split("\\|");
String name = tokens[0];
double salary = Double.parseDouble(tokens[1]);
LocalDate hireDate = LocalDate.parse(tokens[2]);
int year = hireDate.getYear();
int month = hireDate.getMonthValue();
int day = hireDate.getDayOfMonth();
return new Employee(name, salary, year, month, day);
}
/** split方法的参数是一个描述分隔符的正则表达式,
* 碰巧的是,
* 竖线(|)在正则表达式中具有特殊的含义,
* 因此需要用\字符来表示转义,
* 而这个\又需要另一个\来转义,
* 因此产生了“\\|”表达式。
*/
2.1.8 字符编码方式
- 最常见的编码方式是UTF-8,它将每个Unicode编码点编码为1到4个字节的序列。UTF-8的好处是传统的包含了英语中用到的所有字符的ASCII字符集中的每个字符都只会占用一个字节。
- UTF-16,它会将每个Unicode编码点编码为1个或2个16位值。
- StandardCharsets类具有类型为Charset的静态变量,用于表示每种Java虚拟机都必须支持的字符编码方式:
StandardCharsets.UTF_8
StandardCharsets.UTF_16
StandardCharsets.UTF_16BE
StandardCharsets.UTF_16LE
StandardCharsets.ISO_8859_1
StandardCharsets.US_ASCII
- 静态的forName方法可以获得另一种编码方式的Charset
Charset shiftJIS = Charset.forName("Shift-JIS");
- 在读入或写出文本时,使用Charset对象。
var str = new String(bytes, StandardCharsets.UTF_8);
// 将一个字节数组转换为字符串
2.2 读取二进制数据
2.2.1 DataInput和DataOutput接口
- DataOutput接口定义了下面用于以二进制格式写数组、字符、boolean值和字符串的方法:
writeInt writeDouble
writeShort writeChar
writeLong writeBoolean
writeFloat writeUTF
writeChars writeByte
// 例如,writeInt总是将一个整数写出为4字节的二进制数量值,而不管它有多少位。
- 为了读回数据,可以使用在DataInput接口中定义的下列方法:
readInt readDouble
readShort readChar
readLong readBoolean
readFloat readUTF
- example
/** DataInputStream类实现了DataInput接口,
* 为了从文件中读入二进制数据,
* 可以将DataInputStream与某个字节源相组合,
* 例如FileInputStream:
*/
var in = new DataInputStream(new FileInputStream("employee.dat"));
/** 类似地,
* 要写出二进制数据,
* 可以使用实现了DataOutput接口的DataOutputStream类:
*/
var out = new DataOutputStream(new FileOutputStream("employee.dat"));
2.2.2 随机访问文件
- RandomAccessFile类可以在文件中的任何位置查找或写入数据。
var in = new RandomAccessFile("employee.dat", "r");
var inOut = new RandomAccessFile("employee.dat", "rw");
// r表示只读(read),rw表示读写(read and write)
- 随机访问文件有一个表示下一个将被读入或写出的字节所处位置的文件指针,seek方法用来将这个指针设置到文件中的任意的字节位置,seek的参数是一个long类型的整数,它的值位于0到文件按照字节来度量的长度之间。
- getFilePointer方法将返回文件指针的当前位置。
2.2.3 ZIP文档
- ZIP文档(通常)以压缩格式存储了一个或多个文件,每个ZIP文档都有一个头,包含诸如每个文件名字和所使用的压缩方法等信息。
- 读入:
var zin = new ZipInputStream(new FileInputStream(zipname));
ZipEntry entry;
while ((entry = zin.getNextEntry()) != null) {
read the contents of zin
zin.closeEntry();
}
zin.close();
- 写出:
var fout = new FileOutputStream("test.zip");
var zout = new ZipOutputStream(fout);
for all files
{
var ze = new ZipEntry(filename);
zout.putNextEntry(ze);
send data to zout
zout.closeEntry();
}
zout.close();
2.3 对象输入/输出流与序列化
- Java语言支持一种称为对象序列化(object serialization)的非常通用的机制,它可以将任何对象写出到输出流中,并在之后将其返回。
2.3.1 保存和加载序列化对象
- 写出:
// 创建一个ObjectOutputStream对象
var out = new ObjectOutputStream(new FileOutputStream("employee.dat");
// 使用writeObject方法保存对象
var harry = new Employee("Harry Hacker", 50000, 1989, 10, 1);
var boss = new Manager("Carl Cracker", 80000, 1987, 12, 15);
out.writeObject(harry);
out.writeObject(boss);
- 读入:
// 创建一个ObjectInputStream对象
var in = new ObjectInputStream(new FileInputStream("employee.dat"));
// 使用readObject方法获得对象
var e1 = (Employee) in.readObject();
var e2 = (Employee) in.readObject();
- 每个对象都是用一个序列号(serial number)保存的。序列化对象算法:
- 对于遇到的每一个对象引用都关联一个序列号。
- 对于每个对象,当第一次遇到时,保存其对象数据到输出流中。
- 若某个对象之前已经被保存过,那么只写出“与之前保存过的序列号为x的对象相同”。
- 在读回对象时,整个过程反过来:
- 对于对象输入流中的对象,在第一次遇到其序列号时,构建它,并使用流中数据来初始化它,然后记录这个顺序号和新对象之间的关联。
- 当遇到“与之前保存过的序列号为x的对象相同”这一标记时,获取与这个序列号相关联的对象引用。
2.4 操作文件
- Path和Files类封装了在用户机器上处理文件系统所需的所有功能。
2.4.1 Path
- 静态的Paths.get方法接受一个或多个字符串,并将它们用默认文件系统的路径分隔符(类UNIX文件系统是/,Windows是\)连接起来。
Path absolute = Paths.get("/home", "harry");
Path relative = Paths.get("myprog", "conf", "user.properties");
- 相关方法:
/** 1. resolve方法
* 调用p.resolve(q)将按照下列规则返回一个路径:
* 若q是绝对路径,则结果就是q。
* 否则,根据文件系统的规则,将“p后面跟着q”作为结果。
*/
Path workRelative = Paths.get("work");
Path workPath = basePath.resolve(workRelative);
// resolve方法有一种快捷方式,它接受一个字符串而不是路径。
Path workPath = basePath.resolve("work");
/** 2. resolveSibling方法
* 若workPath是 /opt/myapp/wokr ,
* 下面的调用,
* 将创建 /opt/myapp/temp 。
*/
Path tempPath = workPath.resolveSibling("temp");
/** 3. relativize方法
* 以“/home/harry”为目标对“/home/fred/input.txt”进行相对化操作,
* 会产生“../fred/input.txt”,
* 其中,假设..表示文件系统中的父目录。
**/
/** 4. normalize方法
* 该方法会移除所有冗余的.和.. ,
* 规范化 /home/harry/../fred/./input.txt ,
* 将产生 /home/fred/input.txt 。
*/
/** 5. toAbsolutePath方法
* 将产生给定路径的绝对路径。
*/
2.4.2 读写文件
- Files类可以使得普通文件操作变得快捷。
// 读取文件的所有内容
byte[] bytes = Files.readAllBytes(path);
// 从文本文件中读取内容
var content = Files.readString(path, charset);
// 将文件当作行序列读入
List<String> lines = Files.readAllLines(path, charset);
// 写出一个字符串到文件中
Files.writeString(path, content.charset);
// 向指定文件追加内容
Filse.write(path, content.getBytes(charset), StandardOpenOption.APPEND);
// 将一个行的集合写出到文件中
Files.write(path, lines, charset);
/** 以上简便方法适用于处理中等长度的文本文件,
* 若要处理文件长度比较大,
* 或者是二进制文件,
* 那么还是应该使用输入/输出流或者读入器/写出器:
*/
InputStream in = Files.newInputStream(path);
OutputStream out = Files.newOutputStream(paht);
Reader in = Files.newBufferedReader(path, charset);
Writer out = Files.newBufferedWriter(path, charset);
2.4.3 创建文件和目录
// 1. 创建新目录
/** createDirecoty方法
* F:\\IDEAWORKSPACE\\TestDemo文件夹已经存在 \\newDir不存在
***************************************************************
* String pathstr = "F:\\IDEAWORKSPACE\\TestDemo\\newDir";
* Path path = Paths.get(pathstr);
*/
Files.createDirecoty(path);
/** createDirecoties方法
* F:\\IDEAWORKSPACE\\TestDemo路径已经存在 \\midDir\\newDir不存在
***************************************************************
* String pathstr = "F:\\IDEAWORKSPACE\\TestDemo\\midDir\\newDir";
* Path path = Paths.get(pathstr);
*/
Files.createDirecoties(path);
// 2. 创建文件
/** createFile方法
* F:\\IDEAWORKSPACE\\TestDemo路径已经存在 myfile.txt不存在
***************************************************************
* String pathstr = "F:\\IDEAWORKSPACE\\TestDemo\\myfile.txt";
* Path path = Paths.get(pathstr);
*/
Files.createFile(path);
// 会在指定路径下创建myfile.txt空文件
- 有些便捷方法可以用来在给定个位置或者系统指定位置创建临时文件或者临时目录:
Path newPath = Files.createTempFile(dir, prefix, suffix);
Path newPath = Files.createTempFile(prefix, suffix);
Path newPath = Files.createTempDirectory(dir, prefix);
Path newPath = Files.createTempDirectory(prefix);
/** dir是一个Path对象,prefix和suffix是可以为null的字符串。
* 例如,调用Files.createTempFile(null, ".txt")
* 可能会返回一个像 /temp/1234405522364837194.txt 这样的路径。
*/
2.4.4 复制、移动和删除文件
// 1. 复制
Files.copy(fromPath, toPath);
// 2. 移动
Files.move(fromPath, toPath);
/** 若目标路径已经存在,
* 则复制或移动将失败。
* 若要覆盖已有的目标路径,
* 可以使用REPLACE_EXISTING选项。
* 若要复制所有的文件属性,
* 可以使用COPY_ATTRIBUTES选项。
*/
Files.copy(fromPath, toPath, StandardCopyOption.REPLACE_EXISTING, StandardCopyOption.COPY_ATTRIBUTES);
/** 将操作定义为原子性的,
* 以此保证要么移动操作成功完成,
* 要么源文件继续保持在原来位置。
* 使用ATOMIC_MOVE实现。
*/
Files.move(fromPath, toPath, StandardCopyOption.ATOMIC_MOVE);
/** 将一个输入流复制到Path中,
* 表示想要将该输入流存储到硬盘上。
* 类似地,可以将一个Path复制到输出流中。
*/
Files.copy(inputStream, toPath);
Files.copy(fromPath, outputStream);
// 3. 删除
Files.delete(path); // 文件不存在会报错
// 使用deleteIfExists方法
boolean deleted = Files.deleteIfExists(path);
- 用于文件操作的标准选项
| 选项 | 描述 |
|---|---|
| StandardOpenOption | 与newBufferedWriter、newInputStream、newOutputStream、write一起使用 |
| READ | 用于读取而打开 |
| WRITE | 用于写入而打开 |
| APPEND | 如果用于写入而打开,那么在文件末尾追加 |
| TRUNCATE_EXISTING | 如果用于写入而打开,那么移除已有内容 |
| CREATE_NEW | 创建新文件并且在文件已存在的情况下会创建失败 |
| CREAT | 自动在文件不存在的情况下创建新文件 |
| DELETE_ON_CLOSE | 当文件被关闭时,尽“可能”地删除该文件 |
| SPARSE | 给文件系统一个提示,表示该文件是稀疏的 |
| DSYNC或SYNC | 要求对文件数据|数据和元数据的每次更新都必须同步地写入到存储设备中 |
| StandardCopyOption | 与copy和move一起使用 |
| ATOMIC_MOVE | 原子性地移动文件 |
| COPY_ATTRIBUTES | 复制文件的属性 |
| REPLACE_EXISTING | 如果目标已存在,则替换它 |
| LinkOption | 与上面所有方法以及exists、isDirectory、isRegularFile等一起使用 |
| NOFOLLOW_LINKS | 不要跟踪符号链接 |
| FileVisitOption | 与find、walk、walkFileTree一起使用 |
| FOLLOW_LINKS | 跟踪符号链接 |
2.4.5 获取文件信息
/** 1.
* 以下静态方法都将返回一个boolean值,
* 表示检查路径的某个属性的结果。
*/
exists
isHidden
isReadablle,isWritable,isExecutable
isRegularFile,isDirectory,isSymbolicLink
/** 2. size方法
* 返回文件的字节数。
*/
long fileSize = Files.size(path);
/** 3. getOwner方法
* 将文件拥有者作为java.nio.file.attribute.UserPrincipal的一个实例返回。
*/
- 基本文件属性包括:
- 创建文件、最后一次访问以及最后一次修改文件的时间,这些时间都表示成java.nio.file.attribute.FileTime。
- 文件是常规文件、目录还是符号链接,抑或这三者都不是。
- 文件尺寸。
- 文件主键,这是某种类的对象,具体所属类与文件系统相关,有可能是文件的唯一标识符,也可能不是。
// 获取这些属性,可以调用
BasicFileAttributes attributes = Files.readAttributes(path, BasicFileAttributes.class);
// 若文件系统兼容POSIX,那么可以获得一个PosixFileAttributes实例
PosixFileAttributes attributes = Files.readAttributes(path, PosixFileAttributes.class);
2.4.6 访问目录中的项
/** 静态的Files.list方法
* 返回一个可以读取目录中各个项的Stream<Path>对象
*/
try (Stream<Path> entries = Files.list(pathToDirectory)) {
...
}
// list方法不会进入子目录。
/** Files.walk方法
* 处理目录中的所有子目录
*/
try (Stream<Path> entries = Files.walk(pathToRoot)) {
// Contains all descendants, visited in depth-first order
}
2.4.7 使用目录流
- 使用Files.newDirectoryStream对象,实现对遍历过程更加细粒度的控制。
try (DirectoryStream<Path> entries = Files.newDirectorySystem(dir)) {
for (Path entry : entries)
Process entries
}
// 可以用glob模式来过滤文件
try (DirectoryStream<Path> entries = Files.newDirectorySystem(dir, "*.java"))
- 所有glob模式
| 模式 | 描述 | 示例 |
|---|---|---|
| * | 匹配路径组成部分中0个或多个字符 | *.java匹配当前目录中所有Java文件 |
| ** | 匹配跨目录边界的0个或多个字符 | **.java匹配在所有子目录中的Java文件 |
| ? | 匹配一个字符 | ????.java匹配所有四个字符的Java文件 |
| [...] | 匹配一个字符集合,可以使用连线符[0-9]和取反符[!0-9] | Test[0-9A-F]匹配Testx.java,其中x是一个十六进制数字 |
| {...} | 匹配由都好隔开的多个可选项之一 | *.{java,class}匹配所有的Java文件和Class文件 |
| \ | 转义上述任意模式中的字符以及\字符 | *\**匹配所有文件名中包含*的文件 |
2.4.8 ZIP文件系统
FileSystem fs = FileSystems.newFileSystem(Paths.get(zipname), null);
/** 以上调用将建立一个文件系统,
* 它包含ZIP文档中的所有文件。
* 其中zipname是某个ZIP文件的名字。
*/
// 已知文件名,从ZIP文档中复制出这个文件
Files.copy(fs.getPath(sourceName), targetPath);
// 其中的fs.getPath对于任意文件系统来说都与Paths.get类似
2.5 内存映射文件
- 大多数操作系统都可以利用虚拟内存来实现将一个文件或者文件的一部分“映射”到内存中。然后,该文件就可以被当作内存数组一样地访问,这比传统的文件操作要快得多。
2.5.1 内存映射文件的性能
/** 首先,从文件中获得一个通道(channel),
* 通道是用于磁盘文件的一种抽象,
* 可以访问诸如内存映射、文件加锁机制以及文件间快速数据传递等操作系统特性。
*/
FileChannel channel = FileChannel.open(path, options);
/** 然后,通过调用FileChannel类的map方法从这个通道中获得一个ByteBuffer。
* 可以指定映射的文件区域和映射模式,
* 支持的模式有三种:
* 1. FileChannel.MapMode.READ_ONLY:所产生的缓冲区是只读的,任何对该缓冲区写入的尝试都会导致ReadOnlyBufferException异常。
* 2. FileChannel.MapMode.READ_WRITE:所产生的缓冲区是可写的,任何修改都会在某个时段写回到文件中。
* 3. FileChannel.MapMode.PRIVATE:所产生的缓冲区是可写的,但是任何修改对这个缓冲区来说都是私有的,不会传播到文件中。
* 一旦有了缓冲区,就可以使用ByteBuffer类和Buffer超类的方法读写数据了。
*/
- 缓冲区支持顺序和随机数据访问,它有一个可以通过get和put操作来移动的位置。
// 顺序遍历缓冲区中的所有字节
while (buffer.hasRemaining()) {
byte b = buffer.get();
...
}
// 随机访问
for (int i = 0; i < buffer.limit(); i++) {
byte b = buffer.get(i);
...
}
2.5.2 缓冲区数据结构
- 缓冲区是由具有相同类型的数值构成的数组,Buffer类是一个抽象类,它有众多的具体子类,包括ByteBuffer、CharBuffer、DoubleBuffer、IntBuffer、LongBuffer和ShortBuffer。
- 在实践中最常用的将是ByteBuffer和CharBuffer。如图所示,每个缓冲区都具有:
- 一个容量,它永远不能改变。
- 一个读写位置,下一个值将在此进行读写。
- 一个界限,超过它进行读写是没有意义的。
- 一个可选的标记,用于重复一个读入或写出操作。
这些值满足:0 ≤ 标记 ≤ 读写位置 ≤ 界限 ≤ 容量

2.6 文件加锁机制
假设一个应用程序将用户的偏好存储在一个配置文件中,当用户调用这个应用的两个实例时,这两个实例就有可能会同时希望写配置文件。在这种情况下,第一个实例应该锁定文件,当第二个实例发现文件被锁定时,它必须决策是等待直至文件解锁,还是直接跳过这个写操作过程。
/** 1. 锁定文件
* 可以调用FileChannel类的lock或tryLock方法
*/
// A. 阻塞直至可获得锁
FileChannel = FileChannel.open(path);
FileLock lock = channel.lock();
// B. 立即返回 要么返回锁 要么在锁不可获得的情况下返回null
FileLock lock = channel.lock();
/** 2. 锁定文件的一部分
*/
FileLock lock(long start, long size, boolean shared);
// or
FileLock trylock(long start, long size, boolean shared);
/** 如果shared标志为false,
* 则锁定文件的目的是读写。
* 而如果为true,
* 则这是一个共享锁,
* 允许多个进程从文件中读入,
* 并阻止任何进程获得独占的锁。
*/
- 文件加锁机制是依赖于操作系统的,需要注意:
- 在某些系统中,文件加锁仅仅是建议性的,如果一个应用未能得到锁,它仍旧可以向被另一个应用并发锁定的文件执行写操作。
- 在某些系统中,不能在锁定一个文件的同时将其映射到内存中。
- 文件锁是由整个Java虚拟机持有的。如果有两个程序是由同一个虚拟机启动的,那么它们不可能每一个都获得一个在同一个文件上的锁。当调用lock和trylock方法时,如果虚拟机已经在同一个文件上持有了另一个重叠的锁,那么这两个方法将抛出OverlappingFileLockException。
- 在一些系统中,关闭一个通道会释放由Java虚拟机持有的底层文件上的所有锁。因此,在同一个锁定文件上应避免使用多个通道。
- 在网络文件系统上锁定文件是高度依赖于系统的,因此应该尽量避免。
2.7 正则表达式
- 正则表达式(regular expression)用于指定字符串的模式,可以在任何需要定位匹配某种特定模式的字符串的情况下使用正则表达式。
2.7.1 正则表达式语法
- 字符类是一个括在括号中的可选择的字符集。例如,[Jj]、[0-9]、[A-Za-z]或[^0-9]。这里“-”表示是一个范围,而“^”表示补集。
- 如果字符类中包含“-”,那么它必须是第一项或是最后一项;如果要包含“[”,那么它必须是第一项;如果要包含“^”,那么它可以是除开始位置之外的任何位置。其中,只需要转义“[”和“\”。
- 有许多预定义的字符类,例如\d(数字)和\p{Sc}(Unicode货币符号)。
- 语法总结:
- 大部分字符都可以与它们自身匹配。
- .符号可以匹配任何字符(有可能不包括行终止符,这取决于标志的设置)。
- 使用\作为转义字符,例如\.匹配句号而\\匹配反斜线。
- ^和$分别匹配一行的开头和结尾。
- 如果X和Y是正则表达式,那么XY表示“任何X的匹配后面跟随Y的匹配”,X|Y表示“任何X或Y的匹配”。
- 可以将量词运用到表达式X:X+(1个或多个)、X*(0个或多个)与X?(0个或1个)。
- 默认情况下,量词要匹配能够使整个匹配成功的最大可能的重复次数。
- 我们使用群组来定义子表达式,其中群组用括号()括起来。
2.7.2 匹配字符串
- 正则表达式最简单的用法就是测试某个特定的字符串是否与它匹配。
/** 首先用表示正则表达式的字符串构建一个Pattern对象。
* 然后从这个模式中获得一个Matcher,
* 并调用它的mathes方法。
*/
Pattern pattern = Pattern.compile(patternString);
Matcher matcher = pattern.matcher(input);
if (matcher.matchers()) ...
- 在编译这个模式时,可以设置一个或多个标志:
Pattern pattern = Pattern.compile(expression, Pattern.CASE_INSENSITIVE + Pattern.UNICODE_CASE);
// 或者可以在模式中指定它们
String regex = "(?iU:expression)";
- 各个标志:
- Pattern.CASE_INSENSITIVE或i:匹配字符时忽略字母的大小写,默认情况下,这个标志只考虑US ASCII字符。
- Pattern.UNICODE_CASE或u:当与CASE_INSENSITIVE组合使用时,用Unicode字母的大小写来匹配。
- Pattern.UNICODE_CHARACTER_CLASS或U:选择Unicode字符类代替POSIX,其中蕴含了UNICODE_CASE。
- Pattern.MULTILINE或m:^和$匹配行的开头和结尾,而不是整个输入的开头和结尾。
- Pattern.UNIX_LINES或d:在多行模式中匹配^和$时,只有’\n’被识别成行终止符。
- Pattern.DOTALL或s:当使用这个标志时,.符号匹配所有字符,包括行终止符。
- Pattern.COMMENTS或x:空白字符和注释(从#到行末尾)将被忽略。
- Pattern.LITERAL:该模式将被逐字地采纳,必须精确匹配,因字母大小写而造成的差异除外。
- Pattern.CANON_EQ:考虑Unicode字符规范的等价性,例如,e后面跟随..(分音符号)匹配ë。
- 在集合或流中匹配元素,可以将模式转换为谓词:
Stream<String> strings = ...;
Stream<String> result = strings.filtter(pattern.asPredicate());
2.7.3 找出多个匹配
- 通常,不希望使用正则表达式来匹配全部输入,而只是想找出输入中一个或多个匹配的子字符串。
/** 使用Matcher类的find方法来查找匹配内容,
* 如果返回true,
* 再使用start和end方法来查找匹配内容,
* 或使用不带引元的group方法来获取匹配的字符串。
*/
while(matcher.find()) {
int start = matcher.start();
int end = matcher.end();
String match = input.group();
...
}
2.7.4 用分隔符来分割
- 将输入按照匹配的分隔符断开,而其他部分保持不变。
/** Pattern.split方法可以自动完成这项任务。
* 调用此方法后可以获得一个剔除分隔符之后的字符串数组:
*/
String input = ...;
Pattern commas = Pattern.compile("\\s*,\\s*");
String[] tokens = commas.split(input)
// "1, 2, 3" turns into ["1", "2", "3"]
// 若有多个标记,那么可以惰性地获取它们:
Stream<String> tokens = commas.splitAsStream(input);
// 若不关心预编译模式和惰性获取,那么可以使用String.split方法:
String[] tokens = input.split("\\s*,\\s*");
// 若输入数据在文件中,那么要使用扫描器:
var in = new Scanner(path, StandardCharsets.UTF_8);
in.useDelimiter("\\s*,\\s*");
Stream<String> tokens = in.tokens();
2.7.5 替换匹配
- Matcher类的replaceAll方法将正则表达式出现的所有地方都用替换字符串来替换。
/** 例如,
* 将所有的数字序列都替换成#字符
*/
Pattern pattern = Pattern.compile("[0-9]+");
Matcher matcher = pattern.matcher(input);
String output = matcher.replaceAll("#");
第3章 XML
XML概述
使用命名空间
XML文档的结构
流机制解析器
解析XML文档
生成XML文档
验证XML文档
XSL转换
使用XPath来定位信息
3.1 XML概述
- 尽管HTML和XML同宗同源,但是两者之间存在着重要的区别:
- 与HTML不同,XML是大小写敏感的。
- 在HTML中,如果上下文可以分清哪里是段落或列表项的结尾,那么结束标签就可以省略,而在XML中结束标签绝对不能省略。
- 在XML中,只有单个标签而没有相对应的结束标签的元素必须以 / 结尾。
- 在XML中,属性值必须用引号括起来。在HTML中,引号是可有可无的。
- 在HTML中,属性名可以没有值。
3.2 XML文件的结构
- XML文档应当以一个文件头开始,例如:
<?xml version="1.0"?>
<!- 或者 -->
<?xml version="1.0" encoding="UTF-8"?>
- 文档头之后通常是文档类型定义(Document Type Definition, DTD),例如:
<!DOCTYPE web-app PUBLIC
"-//Sun Microsystems, Inc.//DTD Web Application 2.2//EN"
"http://java.sun.com/j2ee/dtds/web-app_2_2.dtd">
- 元素可以有子元素(child element)、文本或两者皆有。
- 元素和文本是XML文档“主要的支撑要素”,还有一些其他的要素:
- 字符引用(character reference)的形式是 &#十进制; 或 &#x十六进制; 。
- 实体引用(entity reference)的形式是 &name; 。
- CDATA部分(CDATA Section)用<![CDATA[ 和 ]]>来限定其界限。它们是字符数据的一种特殊形式。可以使用它们来囊括那些含有<、>、&之类字符的字符串,而不必将它们解释为标记,例如:<![CDATA[< & > are my favorite delimities]> 。
- 处理指令(processing instruction)是那些专门在处理XML文档的应用程序中使用的指令,它们由<?和?>来限定其界限。
- 注释(comment)用<!- 和 –>限定其界限,例如: 。注释中不应该含有字符串–。
3.3 解析XML文档
- 要处理XML文档,就要先解析(parse)它。Java提供了两种XML解析器:
- 像文档对象模型(Document Object Model, DOM)解析器这样的树型解析器(tree parse),它们将读入的XML文档转换成树结构。
- 像XML简单API(Simple API for XML, SAX)解析器这样的流机制解析器(streaming parser),它们在读入XML文档时生成相应的事件。
- 要读入一个XML文档,首先需要一个DocumentBuilder对象,可以从DocumentBuilder Factory中得到这个对象,例如:
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
// 现在,可以从文件中读入某个文档:
File f = ...;
Document doc = builder.parse(f);
// 或者,可以用一个URL:
URL u = ...;
Document doc = builder.parse(u);
// 甚至可以指定任意的输入流:
InputStream in = ...;
Document doc = builder.parse(in);
3.4 验证XML文档
- 文档类型定义(DTD)或XML Schema定义包含了用于解释文档应如何构成的规则,这些规则指定了每个元素的合法子元素和属性。
3.4.1 文档类型定义
<!DOCTYPE config SYSTEM "config.dtd">
<!- 或者 -->
<!DOCTYPE config SYSTEM "http://myserver.com/config.dtd">
3.4.2 XML Schema
<?xml version="1.0"?>
<config xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="config.xsd";
...
</config>
3.5 使用XPath来定位信息
- 使用XPath执行下列操作比普通的DOM方式要简单得多:
- 获得文档根节点。
- 获取第一个子节点,并将其转型为一个Element对象。
- 在其所有子节点中定位title元素。
- 获取其第一个子元素,并将其转型为一个CharacterData节点。
- 获得其数据。
3.6 使用命名空间
- Java语言使用包来避免名字冲突。程序员可以为不同的类使用相同的名字,只要它们不在同一个包中即可。XML也有类似的命名空间(namaspace)机制,可以用于元素名和属性名。
第4章 网络
连接到服务器
HTTP客户端
实现服务器
发送E-mail
获取Web数据
4.1 连接到服务器
4.1.1 使用telnet
- telnet是一种用于网络编程的非常强大的调试工具,可以在命令shell中输入telnet来启动它。
在Windows中,需要激活telnet。要激活它,需要到“控制面板”,选择“程序”,点击“打开/关闭Windows特性”,然后选择“Telnet客户端”复选框。
4.1.2 用Java连接到服务器
import java.io.IOException;
import java.net.Socket;
import java.nio.charset.StandardCharsets;
import java.util.Scanner;
public class SocketTest {
public static void main(String[] args) throws IOException {
try (var s = new Socket("time-a.nist.gov", 13);
var in = new Scanner(s.getInputStream(), StandardCharsets.UTF_8))
{
while(in.hasNextLine()) {
String line = in.nextLine();
System.out.println(line);
}
}
}
}
- 关键代码:
var s = new Socket("time-a.nist.gov", 13);
InputStream inStream = s.getInputStream();
/** 第一行代码用于打开一个套接字,
* 它是网络软件中的一个抽象概念,
* 负责启动该程序内部和外部之间的通信。
*/
4.1.3 套接字超时
- 在套接字读取信息时,在有数据可供访问之前,读操作将会被阻塞,并且因为受底层操作系统的限制而最终会导致超时。
- 对于不同的应用,应该确定合理的超时值。然后调用setSoTimeout方法设置这个超时值(单位:毫秒)。
var s = new Socket(...);
s.setSoTimeout(10000); // time out after 10 seconds
4.1.4 因特网地址
- 一个因特网地址由4个字节组成(IPv4,在IPv6中是16个字节)。
/** 1. 静态的getByName方法
* 将返回一个InetAdress对象,
* 该对象封装了一个4字节的序列:14.215.177.38
* (14.215.177.38为百度的IP地址)
*/
InetAddress address = InetAddress.getByNmae("www.baidu.com");
/** 2. getAddress方法
* 访问这些字节。
*/
byte[] addressBytes = address.getAddress();
/** 3. 一些访问量较大的主机名通常会对应多个因特网地址,
* 以实现负载均衡。
* 当访问主机时,
* 会随机选取几种的一个。
* getAllByName方法
* 获得所有主机。
InetAddress[] addresses = InetAddress.getAllByName(host);
/** 4. 静态的getLocalHost方法
* 得到本地主机的地址。
*/
InetAddress address = InetAddress.getLocalHost();
4.2 实现服务器
4.2.1 服务器套接字
- 一旦启动了服务器程序,他便会等待某个客户端连接到它的端口。
import java.io.*;
import java.net.ServerSocket;
import java.net.Socket;
import java.nio.charset.StandardCharsets;
import java.util.Scanner;
public class EchoServer {
public static void main(String[] args) throws IOException {
// establish server socket
try (var s = new ServerSocket(8189)) {
// wait for client connection
try (Socket incoming = s.accept()) {
InputStream inStream = incoming.getInputStream();
OutputStream outStream = incoming.getOutputStream();
try (var in = new Scanner(inStream, StandardCharsets.UTF_8)) {
var out = new PrintWriter(new OutputStreamWriter(outStream, StandardCharsets.UTF_8), true);
out.println("Hello! Enter BYE to exit");
// echo client input
var done = false;
while (!done&&in.hasNextLine()){
String line = in.nextLine();
out.println("Echo: " + line);
if (line.trim().equals("BYE"))
done = true;
}
}
}
}
}
}
4.2.2 为多个客户端服务
- 使用多线程。
import java.io.*;
import java.net.ServerSocket;
import java.net.Socket;
import java.nio.charset.StandardCharsets;
import java.util.Scanner;
public class ThreadedEchoServer {
public static void main(String[] args) throws IOException {
try (var s = new ServerSocket(8189)) {
int i = 1;
while (true) {
Socket incoming = s.accept();
System.out.println("Spawning " + i);
Runnable r = new ThreadedEchoHandler(incoming);
var t = new Thread(r);
t.start();
i++;
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
class ThreadedEchoHandler implements Runnable {
private Socket incoming;
public ThreadedEchoHandler(Socket incoming) {
this.incoming = incoming;
}
@Override
public void run() {
try (InputStream inStream = incoming.getInputStream();
OutputStream outStream = incoming.getOutputStream();
var in = new Scanner(inStream, StandardCharsets.UTF_8);
var out = new PrintWriter(new OutputStreamWriter(outStream, StandardCharsets.UTF_8), true)) {
out.println("Hello! Enter BYE to exit.");
// echo client input
var done = false;
while (!done && in.hasNextLine()) {
String line = in.nextLine();
out.println("Echo: " + line);
if (line.trim().equals("BYE"))
done = true;
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
4.2.3 半关闭
- 半关闭(half-close)提供了这样一种能力:套接字连接的一端可以终止其输出,同时仍旧可以接收来自另一端的数据。
try (var socket = new Socket(host, port)) {
var in = new Scanner(socket.getInputStream(), StandardCharsets.UTF_8);
var writer = new PrintWriter(socket.getOutputStream());
// send request data
writer.print(...);
writer.flush();
socket.shutdownOutput();
// now socket is half-closed
// read response data
while (in.hasNextLine() != null) {
String line = in.nextLine();
...
}
}
4.2.4 可中断套接字
- 为了中断套接字操作,可以使用java.nio包提供的一个特性——SocketChannel类。
SocketChannel channel = SocketChannel.open(new InetSocketAddress(host, port);
/** 若不想处理缓冲区,可以使用Scanner类从SocketChannel中读取信息,
* 因为Scanner有一个带ReadableByteChannel参数的构造器:
*/
var in = new Scanner(channel, StandardCharsets.UTF_8);
/** 通过调用静态方法Channels.newOutputStream,
* 可以将通道转换成输出流。
*/
OutputStream outStream = Channels.newOutputStream(channel);
4.3 获取Web数据
4.3.1 URL和URI
- URL和URLConnection类封装了大量复杂的实现细节,这些细节设计如何从远程站点获取信息。
/** 自字符串构建一个URL对象:
*/
var url = new URL(urlString);
/** URL类中的openStream方法
* 该方法产生一个InputStream对象,
* 如可以用它构建一个Scanner对象。
*/
InputStream inStream = url.openStream();
var in = new Scanner(inStream, StandardCharsets.UTF_8);
- java.net包对统一资源定位符(Uniform Resource Locator, URL)和统一资源标识符(Uniform Resource Identifier, URI)进行了非常有用的区分。
URI是个纯粹的语法结构,包含用来指定Web资源的字符串的各种组成部分。URL是URI的一个特例,它包含了用于定位Web资源的足够信息。
4.3.2 使用URLConnection获取信息
- 当操作一个URLConnection对象时,必须小心地安排操作步骤:
/** 1. 调用URL类中的openConnection方法获得URLConnection对象:
*/
URLConnection connection = url.openConnection();
/** 2. 使用以下方法来设置任意的请求属性:
*/
setDoInput
setDoOutput
setIfModifiedSince
setUseCaches
setAllowUserInteraction
setRequestProperty
setConnectTimeout
setReadTimeout
/** 3. 调用connect方法连接远程资源:
* 除了与服务器建立套接字连接外,
* 该方法还可用于向服务器查询头信息(header information)。
*/
connection.connect();
/** 4. 与服务器建立连接后,
* 可以查询头信息。
* getHeaderFiledKey和getHeaderField这两个方法枚举了消息头的所有字段。
*/
getContentType
getContentLength
getContentEncoding
getDate
getExpiration
getLastModified
/** 5. 最后,访问资源数据。
*/
4.3.3 提交表单数据
-
有许多技术可以让Web服务器实现对程序的调用。其中最广为人知的是Java Servlet、JavaServer Face、微软的ASP(Active Server Pages,动态服务器主页)以及CGI(Common Gateway Interface,通用网管接口)脚本。
-
执行服务器端脚本过程中的数据流
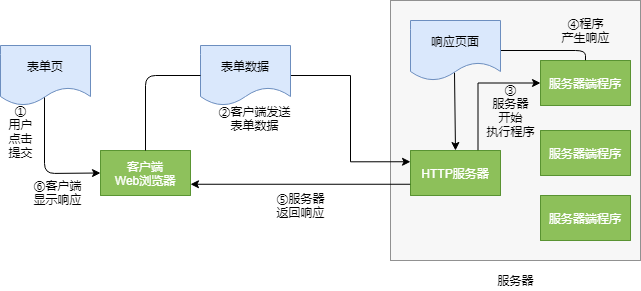
- 详细的过程:
/** 1. 在提交数据给服务器端程序之前,首先需要创建一个URLConnection对象。
*/
var url = new URL("http://host/path");
URLConnection connection = url.openConnection();
/** 2. 然后调用setDoOutput方法建立一个用于输出的连接。
*/
connection.setDoOutput(true);
/** 3. 接着调用getOutputStream方法获得一个流,
* 可以通过这个流向服务器发送数据。
* 如果要向服务器发送文本信息,
* 那么可以非常方便地将流包装在PrintWriter对象中。
*/
var out = new PrintWriter(connection.getOutputStream(), StandardCharsets.UTF_8);
/** 4. 现在,可以向服务器发送数据了。
out.print(name1 + "=" + URLEncoder.encode(value1, StandardCharsets.UTF_8) + "&");
out.print(name2 + "=" + URLEncoder.encode(value2, StandardCharsets.UTF_8);
/** 5. 之后关闭输出流。
*/
out.close();
/** 6. 最后,调用getInputStream方法读取服务器的响应。
*/
4.4 HTTP客户端
- 与URLConnection类相比,HTTP客户端API从设计初始就提供了一种更简单的连接到Web服务器的机制。
/** HttpClient对象可以发出请求并接收响应。
* 可以通过下面的调用获取客户端:
*/
HttpClient client = HttpClient.newHttpClient();
/** 或者,如果需要配置客户端,
* 可以使用像下面这样的构建器API:
*/
HttpClient client = HttpClient.newBuilder()
.followRedirects(HttpClient.Redirect.ALWAYS)
.build();
- URI是指“统一资源标识符”,在使用HTTP时,它与URL相同。
4.5 发送E-mail
- 使用JavaMail API。
第5章 数据库编程
JDBC的设计 可滚动和可更新的结果集
结构化查询语言
行集
JDBC配置
元数据
使用JDBC语句
事务
执行查询操作
Web和企业应用中的连接管理
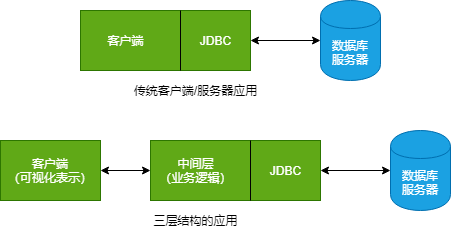
5.1 JDBC的设计
- JDBC和ODBC都基于同一个思想:根据API编写的程序都可以与驱动管理器进行通信,而驱动管理器则通过驱动程序与实际的数据库进行通信。
5.1.1 JDBC驱动程序类型
- JDBC规范将驱动程序归结为以下几类:
- 第1类驱动程序将JDBC翻译成ODBC,然后使用ODBC驱动程序与数据库进行通信。
- 第2类驱动程序是由部分Java程序和部分本地代码组成的,用于与数据库的客户端API进行通信。
- 第3类驱动程序是纯Java客户端类库,它使用一种与具体数据库无关的协议将数据库请求发送给服务器构件,然后该构件再将数据库请求翻译成数据库相关的协议。
- 第4类驱动程序是纯Java类库,它将JDBC请求直接翻译成数据库相关的协议。
- JDBC最终是为了实现以下目标:
- 通过使用标准的SQL语句,甚至是专门的SQL拓展,程序员就可以利用Java语言开发访问数据库的应用,同时还依旧遵守Java语言的相关规定。
- 数据库供应商和数据库工具开发商可以提供底层的驱动程序。因此,他们可以优化各自数据库产品的驱动程序。
5.1.2 JDBC的典型用法
- 三层模式的优点:它将可视化表示(位于客户端)从业务逻辑(位于中间层)和原始数据(位于数据库)中分离出来。
5.2 结构化查询语言
- 按照惯例,SQL关键字全部使用大写字母。如:SELECT, WHERE等。
-
与Java编程语言不同,SQL使用=和<>而非==和!=来进行相等性比较。
- WHERE子句也可以使用LIKE操作符来实现模式匹配,使用“ % ”表示0或多个字符,用“ _ ”表示单个字符。
这条语句将排除所有书名中包含UNIX或者Linux的图书:
SELECT ISBN, Price, Title
FROM Books
WHERE Title NOT LIKE '%n_x%'
- 字符串都是用单引号括起来的,而非双引号。字符串中的单引号则需要用一对单引号代替。
这条语句会返回所有包含单引号的书名:
SELECT Title
FROM Books
WHERE Title LIKE '%''%'
- 常见的SQL数据类型:
| 数据类型 | 说明 |
|---|---|
| INTEGER或INT | 通常为32位的整数 |
| SMALLINT | 通常位16位的整数 |
| NUMERIC(m,n), DECIMAL(m,n)或DEC(m,n) | m位长的定点十进制数,其中小数点后为n位 |
| FLOAT(n) | 运算精度为n位二进制数的浮点数 |
| REAL | 通常为32位浮点数 |
| DOUBLE | 通常为64位浮点数 |
| CHARACTER(n)或CHAR(n) | 固定长度为n的字符串 |
| VARCHAR(n) | 最大长度为n的可变长字符串 |
| BOOLEAN | 布尔值 |
| DATE | 日历日期(与具体的实现相关) |
| TIME | 当前时间(与具体的实现相关) |
| TIMESTAMP | 当前日期和时间(与具体的实现相关) |
| BLOB | 二进制大对象 |
| CLOB | 字符大对象 |
5.3 使用JDBC语句
5.3.1 执行SQL语句
// 将要执行的SQL语句放入字符串中
String command = "UPDATE Books"
+ " SET Price = Price - 5.00 "
+ " WHERE Title NOT LIKE '%Introduction%'";
// 调用Statement接口中的executeUpdate方法
stat.executeUpdate(conmmand);
- executeUpdate方法:既可以执行诸如INSERT、UPDATE和DELETE之类的操作,也可以执行诸如CREATE TABLE和DROP TABLE之类的数据定义语句。
- executeQuery方法:执行SELECT查询。
- execute方法:可以执行任意的SQL语句,此方法只用于由用户提供的交互式查询。
/** executeQuery方法会返回一个ResultSet类型的对象,
* 可以通过它来每次一行地迭代遍历所有查询结果。
*/
ResultSet rs = stat.executeQuery("SELECT * FROM Books");
/** 分析结果集时,
* 通常可以使用类似如下的循环语句代码:
*/
while (rs.next()) {
look at a row of the result set
}
/** 结果集中行的顺序是任意排列的。
* 可以使用ORDER BY子句指定行的顺序。
*/
/** 查看每一行时,
* 可能希望知道每一列的内容,
* 可以使用访问器。
*/
String isbn = rs.getString(1);
double price = rs.getDouble("Price");
// 与数组的索引不同,数据库的序列号是从1开始计算的。
5.3.2 管理连接、语句和结果集
- 每个Connection对象都可以创建一个或多个Statement对象。同一个Statement对象可以用于多个不相关的命令和查询。但是,一个Statement对象最多只能有一个打开的结果集。如果需要执行多个查询操作,且需要同时分析查询结果,那么必须创建多个Statement对象。
5.4 执行查询操作
5.4.1 预备语句
- 在预备查询语句中,每个宿主变量都用“ ? ”来表示。
String publisherQuery
= "SELECT Books.Price, Books"
+ "FROM Books, Publishers"
+ "WHERE Books.Publisher_Id = Publishers.Publisher_Id AND Publisher.Name = ?";
PreparedStatement stat = conn.prepareStatement(publisherQuery);
/** 在执行预备语句之前,
* 必须使用set方法将变量绑定到实际的值上。
* 第一个参数指的是需要设置的宿主变量的位置,
* 位置1表示第一个“ ? ”,
* 第二个参数指的是赋予宿主变量的值。
*/
stat.setString(1, publisher);
5.4.2 读写LOB
- 在SQL中,二进制大对象称为BLOB,字符型大对象称为CLOB。
- 要读取LOB,需要执行SELECT语句,然后再ResultSet上调用getBlob或getClob方法,这样就可以获得Blob或Clob类型的对象。要从Blob中获取二进制数据,可以调用getBytes或getBinaryStream。
/** 例如,有一张保存图书封面图像的表,
* 那么,就可以像下面这样获取一种图像。
*/
PreparedStatement stat = conn.prepareStatement("SELECT Cover FROM BookCovers WHERE ISBN=?");
...
stat.set(1, isbn);
try (ResultSet result = stat.executeQuery()) {
if (result.next()) {
Blob coverBlob = result.getBlob(1);
Image coverImage = ImageIO.read(coverBlob.getBinaryStream());
}
}
- 要将LOB置于数据库中,需要在Connection对象上调用createBlob或createClob方法,然后获取一个用于该LOB的输出流或写出器,写出数据,并将该对象存储到数据库中。
/** 例如,存入一张图像。
*/
Blob coverBlob = connection.createBlob();
int offset = 0;
OutputStream out = coverBlob.setBinaryStream(offset);
ImageIO.write(coverImage, "PNG", out);
PreparedStatement stat = conn.prepareStatement("INSERT INTO Cover VALUES (?,?)");
stat.set(1, isbn);
stat.set(2, coverBlob);
stat.executeUpdate();
5.4.3 SQL转义
- “转义”语法是各种数据库普遍支持的特性,但是数据库使用的是与数据库相关的语法变体,因此,将转义语法转译为特定数据库的语法是JDBC驱动程序的任务之一。
- 转义主要用于下列场景:
日期和时间字面常量
调用标量函数
调用存储过程
外连接
在LIKE子句中的转义字符
- 日期和时间字面常量随数据库数据库的不同而变化很大。要嵌入日期或时间字面常量,需要按照ISO 8601格式( http://www.cl.cam.ac.uk/~mgk25/iso-time.html )指定它的值,之后驱动程序会将其转义为本地格式。应该使用d、t、ts来表示DATE、TIME和TIMESTAMP值:
{d '2008-01-24'}
{t '23:59:59'}
{ts '2008-01-24 23:59:59.999'}
- 标量函数(scalar function)是指仅返回单个值的函数。嵌入标准的函数名和参数:
{fn left(?, 20)}
{fn user()}
- 存储过程(stored procedure)是在数据库中执行的用数据库相关的语言编写的过程。要调用存储过程,需要使用call转义命令,在存储过程没有任何参数时,可以不用加上括号。另外,应该用“=”来捕获存储过程的返回值:
{call PR0C1(?,?)}
{call PR0C2}
{call ? = PR0C3(?)}
-
两个表的外连接(outer join)并不要求每个表的所有行都要根据连接条件进行匹配。
-
_和%字符在LIKE子句中具有特殊含义,用来匹配一个字符或一个字符序列。如将“!”定义为转义字符,则“! _” 组合表示字面常量下划线。
...WHERE ? LIKE %!_% {escape '!'}
5.4.4 多结果集
- 在执行存储过程,或者在使用允许在单个查询中提交多个SELECT语句的数据库时,一个查询有可能会返回多个结果集。下面是获取所有结果集的步骤:
- 使用execute方法来执行SQL语句。
- 获取第一个结果集或更新计数。
- 重复调用getMoreResults方法以移动到下一个结果集。
- 当不存在更多的结果集或更新计数时,完成操作。
boolean isResult = stat.execute(command);
boolean done = false;
while (!done) {
if (isResult) {
ResultSet result = stat.getResultSet();
do something with result
}
else {
int updateCount = stat.getUpdateCount();
if (updateCount >= 0)
do something with updateCount
else
done = true;
}
if (!done) isResult = stat.getMoreResults();
}
5.4.5 获取自动生成的键
- 当向数据表中插入一个新行,且其键自动生成时,可以用下面的代码来获取这个键:
stat.executeUpdate(insertStatement, Statement.RETURN_GENERATED_KEYS);
ResultSet rs = stat.getGeneratedKeys();
if (rs.next()) {
int key = rs.getInt(1);
...
}
5.5 事务
- 可以将一组语句构建成一个事务(transaction)。当所有语句都顺利执行之后,事务可以被提交。否则,如果其中某个语句遇到错误,那么事务将被回滚,就好像没有任何语句被执行过一样。以此来确保数据库完整性(database integrity)。
5.5.1 用JDBC对事务编程
- 默认情况下,数据库连接处于自动提交模式(autocommit mode),即每个SQL语句一旦被执行便提交给数据库。一旦命令被提交,就无法对它进行回滚操作。在使用事务时,需要关闭这个默认值:
conn.setAutoCommit(false);
/** 按照通常的方式创建一个语句对象:
*/
Statement stat = conn.createStatement();
/** 然后任意多次地调用executeUpdate方法:
*/
stat.executeUpdate(command1);
stat.executeUpdate(command2);
stat.executeUpdate(command3);
...
/** 如果执行了所有命令之后没有出错,
* 则调用commit方法:
*/
conn.commit();
/** 如果出现错误,则调用:
*/
conn.rollback();
5.5.2 保存点
- 在使用某些驱动程序时,使用保存点(save point)可以更细粒度地控制回滚操作。创建一个保存点意味着稍后只需要返回到这个点,而非放弃整个事务。
Statement stat = conn.createStatement(); // start transaction; rollback() goes here
stat.executeUpdate(command1);
SavePoint svpt = conn.setSavepoint(); // set savepoint; rollback() goes here
stat.executeUpdate(command2);
if (...) conn.rollback(svpt); // undo effect of command2
...
conn.commit();
// 当不再需要保存点时,应该释放它:
conn.releaseSavepoint(svpt);
5.5.3 批量更新
- 假设有一个程序需要执行许多INSERT语句,以便将数据填入数据库表中,此时可以使用批量更新的方法来提高程序性能。
/** 为了执行批量处理,
* 首先必须使用通常的办法创建一个Statement对象:
*/
Statement stat = conn.createStatement();
/** 现在,应该调用addBatch方法,
* 而非executeUpdate方法:
*/
String command = "CREATE TABLE ..."
stat.addBatch(command);
while (...) {
command = "INSERT INTO ... VALUES (" + ... + ")";
stat.addBatch(command);
}
/** 最后,提交整个批量更新语句:
*/
int[] counts = stat.executeBatch();
5.5.4 高级SQL类型
- SQL数据类型及其对应的Java类型:
| SQL数据类型 | Java数据类型 |
|---|---|
| INTEGER或INT | int |
| SMALLINT | short |
| NUMERIC(m,n), DECIMAL(m,n)或DEC(m,n) | java.math.BigDecimal |
| FLOAT(n) | double |
| REAL | float |
| DOUBLE | double |
| CHARACTER(n)或CHAR(n) | String |
| VARCHAR(n) | String |
| BOOLEAN | boolean |
| DATE | java.sql.Date |
| TIME | java.sql.Time |
| TIMESTAMP | java.sql.Timestamp |
| BLOB | java.sql.Blob |
| CLOB | java.sql.Clob |
| ARRAY | java.sql.Array |
| ROWID | java.sql.RowId |
| NCHAR(n), NVARCHAR(n), LONG NVARCHAR | String |
| NCLOB | java.sql.NClob |
| SQLXML | java.sql.SQLXML |
第6章 日期和时间API
时间线
时区时间
本地日期
格式化和解析
日期调整器
与遗留代码的互操作
本地时间
6.1 时间线
- Java的Date和Time API规范要求Java使用的时间尺度为:
- 每天86 400秒
- 每天正午与官方时间精确匹配
- 在其他时间点上,以精确定义的方式与官方时间接近匹配
- 在Java中,Instant表示时间线上的某个点。Instant的值往回可追溯10亿年(Instant.MIN)。最大的值Instant.MAX是公元1 000 000 000年的12月31日。
/** 静态方法调用Instant.now()会给出当前的时刻。
* 为了得到两个时刻之间的时间差,
* 可以使用静态方法Duration.between。
* 例如,以下代码可以度量算法运行的时间:
*/
Instant start = Instant.now();
runAlgorithm();
Instant end = Instant.now();
Duration timeElapsed = Duration.between(start, end);
long millis = timeElapsed.toMillis();
/** Duration是两个时刻之间的时间量。
* 可以调用toNanos、toMillis、getSeconds、toMinutes、toHour和toDay
* 来获得Duration按照传统单位度量的时间长度。
* tips: 在Java 8中,必须调用getSeconds而不是toSeconds。
*/
/** Duration接口包含了大量的用于执行算术运算的方法。
* 例如,
* 检测某个算法是否至少比另一个算法快10倍。
*/
Duration timeElapsed2 = Duration.between(start2, end2);
boolean overTenTimesFaster
= timeElapsed.multipliedBy(10).minus(timeElapsed2).isNegative();
/** 以上代码仅为展示语法。
* 实际上可以直接调用:
*/
boolean overTenTimesFaster = timeElapsed.toNanos() * 10 < timeElapsed2.toNanos();
6.2 本地日期
- 在Java API中有两种人类时间,本地日期/时间和时区时间。
1903年6月14日是一个本地日期的示例(lambda演算的发明者Alonzo Church在这一天诞生)。
1969年7月16日 09:32:00 EDT(阿波罗11号发射的时刻)是一个时区日期/时间,表示的是时间线上的一个精确的时刻。
- LocalDate是带有年、月、日的日期。为了构建LocalDate对象,可以使用now或of静态方法:
LocalDate today = LocalDate.now(); // Today's date
LocalDate alonzosBirthday = LocalDate.of(1903, 6, 14);
alonzosBirthday = LocalDate.of(1903, Month.JUNE, 14);
// Uses the Month enumeration
- 两个Instant之间的时长是Duration,而用于本地日期的等价物是Period,它表示的是流逝的年、月或日的数量。
birthday.plus(Period.ofYears(1)); // 获得下一年的生日
birthday.plusYears(1); // 获得下一年的生日
birthday.plus(Duration.ofDay(365)); // 在闰年不会产生正确的结果
/** until方法会产生两个本地日期之间的时长。
*/
LocalDate independenceDay = LocalDate.of(2020, 07, 20);
LocalDate christmas = LocalDate.of(2020, 12, 25);
independenceDay.until(christmas); // 会产生5个月5天的一段时长
independenceDay.unitl(christmas, ChronoUnit.DAYS) // 158 days
LocalDate API中有些方法可能会创造出并不存在的日期。这些方法并不会抛出异常,而是会返回该月有效的最后一天。 例如,
LocalDate.of(2016, 1, 31).plusMonths(1);
和
LocalDate.of(2016, 3, 31).minusMonths(1);
都将产生2016年2月29日。
- getDayOfWeek会产生星期日期,即DayOfWeek枚举的某个值。DayOfWeek.MONDAY的枚举值为1,而DayOfWeek.SUNDAY的枚举值为7。
- DayOfWeek枚举具有便捷方法plus和minus,以7为模计算星期日期。例如,DayOfWeek.SATURDAY.plus(3)会产生DayOfWeek.TUESDAY。
周末实际上在每周的末尾。这与java.util.Calendar有所差异,在后者中,星期日的值为1,而星期6的值为7。
- Java 9添加了两个有用的datesUntil方法,它们会产生LocalDate对象流。
LocalDate start = LocalDate.of(2020, 1, 1);
LocalDate endExclusive = LocalDate.now();
Stream<LocalDate> allDays = start.datesUntil(endExclusive);
Stream<LocalDate> firstDaysInMonth = start.datesUntil(endExclusive, Perod.ofMonths(1));
6.3 日期调整器
- 对于日常安排,经常需要计算诸如“每个月的第一个星期二”这样的日期。TemporalAdjusters类提供了大量用于常见调整的静态方法。
/** 可以将调整方法的结构传递给with方法。
* 例如,
* 某个月的第一个星期二:
*/
LocalDate firstTuesday = LocalDate.of(year, month, 1).with(
TemporalAdjusters.nextOrSame(DaysOfWeek.TUESDAY));
- 可以通关实现TemporalAdjuster接口来创建自己的调整器。例如,计算下一个工作日的调整器。
TemporalAdjuster NEXT_WORKDAY = w -> {
var result = (LocalDate) w;
do {
result = result.plusDays(1);
} while (result.getDayOfWeek().getValue() >= 6);
return result;
};
LocalDate backToWork = today.with(NEXT_WORKDAY);
/** lambda表达式的参数类型为Temporal,
* 它必须被强制转型为LocalDate。
*/
- 使用ofDateAdjuster方法可以避免这种强制转型,该方法期望得到的参数类型为UnaryOperator
的lambda表达。
TemporalAdjuster NEXT_WORKDAY = TemporalAdjusters.ofDateAdjuster(w ->
{
LocalDate result = w; // No cast
do {
result = result.plusDays(1);
} while (result.getDayOfWeek().getValue >= 6);
return result;
});
6.4 本地时间
- LocalTime表示当日时刻。可以用now或of方法创建其实例:
LocalTime rightNow = LocalTime.now();
LocalTime bedtime = LocalTime.of(22, 30); // or LocalTime.of(22, 30, 0);
/** plus和minus操作是按照一天24小时循环操作的。
*/
LocalTime wakeup = bedtime.plusHours(8); // wakeup is 6:30:00
6.5 时区时间
- 互联网编码分配管理机构(Internet Assigned Numbers Authority, IANA)保存着一个数据库,里面存储着世界上所有已知的时区(www.iana.org/time-zones),它每年会更新数次,而批量更新会处理夏令时的变更规则。Java使用了IANA数据库。
/** 给定一个时区ID,
* 1. 静态方法ZoneId.of(id)可以产生一个ZoneId对象。
* 2. 调用local.atZone(zoneId)将LocalDateTime对象转换为ZonedDateTime对象,
* 3. 调用静态方法
* ZonedDateTime.of(year, month, day, hour, minute, second, nano, zoneId)
* 来构造一个ZonedDateTime对象。
*/
ZonedDateTime apollo11lauch = ZonedDateTime.of(1969, 7, 16, 9, 32, 0, 0,
ZoneId.of(America/New_York));
// 1969-07-16T09:32-04:00[America/New_York]
/** 这是一个具体的时刻,
* 调用apollo11lauch.toInstant可以获得对于的Instant对象。
* 反过来
* 若有一个时刻对象,
* 调用instant.atZone(ZoneId.of("UTC"))可以获得格林尼治皇家天文台的ZonedDateTime对象。
*/
UTC代表“协调世界时”,这是英文“Coordinated Universal Time”和法文“Temps Universal Coordiné”首字母缩写的折中。UTC是不考虑夏令时的格林尼治皇家天文台时间。
- 夏令时带来的复杂性:
/** 当夏令时开始时,
* 时钟要向前拨快一小时。
* 例如,
* 在2013年,中欧地区在3月31日2:00切换到夏令时,
* 若视图构建的时间是不存在的3月31日 2:30,
* 那么实际上得到的是3:30。
*/
ZonedDateTime skipped = ZonedDateTime.of(
LocalDate.of(2013, 3, 31),
LocalTime.of(2, 30),
ZonedId.of("Europe/Berlin"));
// Constructs March 31 3:30
/** 返过来,
* 当夏令时结束时,
* 时钟要向回拨慢一小时,
* 同一个本地时间就会出现两次。
* 当构建位于这个时间段内的时间对象时,
* 就会得到这个两个时刻中较早的一个。
*/
ZonedDateTime ambiguous = ZonedDateTime.of(
LocalDate.of(2013, 10, 27), // End of daylight savings time
LocalTime.of(2, 30),
ZoneId.of("Europe/Berlin"));
// 2013-10-27T02:30+02:00[Europe/Berlin]
ZonedDateTime anHourLater = ambiguous.plusHours(1);
// 2013-10-27T02:30+01:00[Europe/Berlin]
/** 在调整跨越夏令时边界的日期时需要特别注意。
* 例如,
* 如果将会议设置在下个星期,
* 不要直接加上一个7天的Duration:
*/
ZonedDateTime nextMeeting = meeting.plus(Duration.ofDays(7));
// Caution! Won't work with daylight savings time
/** 而应该使用Period类
*/
ZonedDateTime nextMeeting = meeting.plus(Period.ofDays(7)); // OK
6.6 格式化和解析
- DateTimeFormatter类提供了三种用于打印日期/时间值的格式器:
- 预定义的格式器
- locale相关的格式器
- 带有定制模式的格式器
- 预定义的格式器:
| 格式器 | 描述 | 示例 |
|---|---|---|
| BASIC_ISO_DATA | 年、月、日、时区偏移量, 中间没有分隔符 |
19690716-0500 |
| ISO_LOCAL_DATE, ISO_LOCAL_TIME, ISO_LOCAL_DATE_TIME |
分隔符为-、:、T | 1969-07-16, 09:32:00 1969-07-16T09:32:00 |
| ISO_OFFSET_DATE, ISO_OFFSET_TIME, ISO_OFFSET_DATE_TIME |
类似ISO_LOCAL_XXX, 但是有时区偏移量 |
1969-07-16-05:00, 09:32:00-05:00, 1969-07-16T09:32:00-05:00 |
| ISO_ZONED_DATE_TIME | 有时区偏移量和 时区ID |
1969-07-16T09:32:00-05:00 [Americal/New York] |
| ISO_INSTANT | 在UTC中, 用Z时区ID来表示 |
1969-07-16T14:32:00Z |
| ISO_DATE, ISO_TIME, ISO_DATE_TIME |
类似 ISO_OFFSET_DATE、 ISO_OFFSET_TIME 和 ISO_ZONED_DATE_TIME, 但是时区信息是可选的 |
1969-07-16-05:00, 09:32:00-05:00, 1969-07-16T09:32:00-05:00 [Americal/New York] |
| ISO_ORDINAL_DATE | LocalDate的年和年日期 | 1969-197 |
| ISO_WEEK_DATE | LocalDate的年、星期和 星期日期 |
1969-W29-3 |
| RFC_1123_DATE_TIME | 用于邮件时间戳的标准, 编纂于RFC822, 并在RFC1123中 将年份更新到4位 |
Wed, 16 Jul 1969 09:32:00 -0500 |
/** 要使用标准的格式器,
* 可以直接调用其format方法:
*/
String formatted = DateTimeFormatter.ISO_OFFSET_DATE_TIME.format(appllo11lauch);
// 1969-07-16T09:32:00-04:00
- locale相关的格式化风格:
| 风格 | 日期 | 时间 |
|---|---|---|
| SHORT | 7/16/69 | 9:32 AM |
| MEDIUM | Jul 16, 1969 | 9:32:00 AM |
| LONG | July 16, 1969 | 9:32:00 AM EDT |
| FULL | Wednesday, July 16, 1969 | 9:32:00 AM EDT |
/** 静态方法ofLocalizedDate、ofLocalizedTime和ofLocalizedDateTime可以创建这种格式器。
*/
DateTimeFormatter formatter = DateTimeFormatter.ofLocalizedDateTime(FormatStyle.LONG);
String fromatted = formatter.format(appllo11lauch);
// July 16, 1969 9:32:00 AM EDT
/** 这些方法使用了默认的locale。
* 为了切换到不同的locale,
* 可以直接使用withLocale方法。
formatted = formatter.withLocale(Locale.FRENCH).format(apollo11lauch);
// 16 juillet 1969 09:32:00 EDT
/** DayOfWeek和Month枚举都有getDisplayName方法,
* 可以按照不同的locale和格式给出星期日期和月份的名字。
*/
for (DayOfWeek w : DayOfWeek.values())
System.out.print(w.getDisplayName(TextStyle.SHORT, Locale.ENGLISH) + " ");
// Prints Mon Tue Wed Thu Fri Sat Sun
- 定制模式的日期格式:
formatter = DateTimeFormatter.ofPattern("E yyyy-MM-dd HH:mm");
6.7 与遗留代码的互操作
-
作为全新的创造,Java Date和Time API必须能够与已有类之间进行互操作,特别是无处不在的java.util.Date、java.util.GregorianCalendar和java.sql.Date/Time/Timestamp。
-
java.time类与遗留类之间的转换:
| 类 | 转换到遗留类 | 转换自遗留类 |
|---|---|---|
| Instant ⇋ java.util.Date |
Date .from(instant) |
date .toInstant() |
| ZonedDateTime ⇋ java.util.GregorianCalendar |
GregorianCalendar .from( zonedDateTime) |
cal .toZonedDateTime() |
| Instant ⇋ java.sql.Timestamp |
TimeStamp .from(instant) |
timestamp .toInstant() |
| LocalDateTime ⇋ java.sql.Timestamp |
Timestamp .valueOf( localDateTime) |
timeStamp .toLocalDateTime() |
| LocalDate ⇋ java.sql.Date |
Date .valueOf(localDate) |
date .toLocalDate() |
| LocalTime ⇋ java.sql.Time |
Time .valueOf(localTime) |
time .toLocalTime() |
| DateTimeFormatter ⇋ java.text.DateFormat |
formatter .toFormat() |
无 |
| java.util.TimeZone ⇋ ZoneId |
Timezone .getTimeZone(id) |
timeZone .toZoneId() |
| java.nio.file.attribute.FileTime ⇋ Instant |
FileTime .from(instant) |
fileTime .toInstant() |
第7章 国际化
locale
消息格式化
数字格式
文本输入和输出
日期和时间
资源包
排序和规范化
- 从一开始,Java就具备了进行有效的国际化所必需的一个重要特性:使用Unicode来处理所有字符串。由于支持Unicode,在Java编程语言中编写程序来操作多种语言的字符串变得异常方便。
7.1 locale
7.1.1 为什么需要locale
- 当提供一个程序的国际化版本时,所有程序消息都需要转换为本地语言。当然直接翻译用户界面的文本是不够的。
例如,对于德国用户,数字 123,456.78 应该显示为 123.456,78(小数点和十进制数的逗号分隔符的角色是相反的)。
又例如,在美国,日期的显示为月/日/年;在德国,日期的显示为日/月/年;而在中国,则使用年/月/日。
7.1.2 指定locale
- locale由多达5个部分构成:
- 一种语言,由2个或3个小写字母表示,如en(英语)、de(德语)和zh(中文)。
- 可选的一段文本,由首字母大写的四个字母表示,例如Latn(拉丁文)、Cyrl(西里尔文)和Hant(繁体中文)。
- 可选的一个国家或地区,由2个大写字母或3个数字表示,例如US(美国)和CH(瑞士)。
- 可选的一个变体,用于指定各种杂项特性,例如方言和拼写规则。
- 可选的一个扩展。扩展描述了日历(如中国农历)和数字(替代西方数字的泰语数字)等内容的本地偏好。
- locale是用标签描述的, 标签是由locale的各个元素通过连字符连接起来的字符串,例如en-US。
在德国,你可以使用de-DE。瑞士有4种官方语言(德语、法语、意大利语和里托罗曼斯语)。在瑞士讲德语的人希望使用的locale是de-CH。这个locale会使用德语的规则,但是货币值会表示成瑞士法郎而不是欧元。
// 用标签字符串来构建Locale对象
Locale usEnglish = Locale.forLanguageTag("en-US");
// toLanguageTag方法可以生成给定locale的语言标签
Local.US.toLanguageTag(); // 生成字符串"en-US"
7.1.3 默认locale
- Locale类的静态getDefault方法可以获得作为本地操作系统的一部分而存放的默认locale。
- 有些操作系统允许用户为显示消息和格式化指定不同的loclae。
// 获取这些偏好,可以调用
Locale displayLocale = Locale.getDefault(Locale.Category.DISPLAY);
Locale formatLocale = Locale.getDefault(Locale.Category.FORMAT);
7.2 数字格式
- Java类库提供了一个格式器(formatter)对象的集合,它可以对java.text包中的数字值进行格式化和解析。
7.2.1 格式化数字值
- 可以通过下面的步骤对特定locale的数字进行格式化:
- 得到Locale对象。
- 使用一个“工厂方法”得到一个格式器对象。
- 使用这个格式器对象来完成格式化和解析工作。
/** 工厂方法是NumberFormat类的静态方法,
* 它们接受一个Locale类型的参数。
* 总共有3个工厂方法getNumberInstance、
* getCurrencyInstance和getPercentInstance,
* 这些方法返回的对象可以分别对
* 数字、货币量和百分比进行格式化和解析。
*/
Locale loc = Locale.GERMAN;
NumberFormat currFmt = NumberFormat.getCurrencyInstance(loc);
double amt = 123456.78;
String result = currFmt.format(amt);
// 结果是 123.456,78 €
/** 相反,
* 如果想读取一个按照某个locale的惯用法而输入或存储的数字,
* 那么就需要使用parse方法。
*/
TextField inputField;
...
NumberFormat fmt = NumberFormat.getNumberInstance();
// get the number formatter for default locale
Number input = fmt.parse(inputField.getText().trim());
double x = input.doubleValue();
7.2.2 货币
/** 假设为一个美国客户准备了一张货物单,
* 货物单中有些货物的金额是用美元表示的,
* 有些是用欧元表示的,此时,
* 你不能只是使用两种格式器:
*/
NumberFormat dollarFormatter = NumberFormat.getCurrencyInstance(Locale.US);
NumberFormat euroFormatter = NumberFormat.getCurrencyInstance(Locale.GERMANY);
/** 这会导致发票看起来非常奇怪,
* 有些金额的格式像 $ 100,000,
* 另一些则像100.000 €(注意:欧元值使用小数点而不是逗号作为分隔符)。
*/
/** 应当使用Currency类来控制被格式器处理的货币。
* 为美国客户设置欧元格式:
*/
NumberFormat euroFormatter = NumberFormat.getCurrencyInstance(Locale.US);
euroFormatter.setCurrency(Currency.getInstance("EUR"));
- 货币标识符:
| 货币值 | 标识符 | 货币代码 |
|---|---|---|
| U.S. Dollar | USD | 840 |
| Euro | EUR | 978 |
| British Pound | GBP | 826 |
| Japanese Yen | JPY | 392 |
| Chinese Renmingbi(Yuan) | CNY | 156 |
| Indian Rupee | INR | 356 |
| Russian Ruble | RUB | 643 |
7.3 日期和时间
- 当格式化日期和时间时,需要考虑4个与locale相关的问题:
- 月份和星期应该用本地语言来表示。
- 年、月、日的顺序要符合本地习惯。
- 公历可能不是本地首选的日期表示方法。
- 必须考虑本地区的时区。
- java.time包中的DateTimeFormatter类可以处理这些问题(6.6节)。
FormatStyle style = ...; // One of FormatStyle.SHORT, FormatStyle.MEDIUM, ...
DateTimeFormatter dateFormatter = DateTimeFormatter.ofLocalizedDate(style);
DateTimeFormatter timeFormatter = DateTimeFormatter.ofLocalizedTime(style);
DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofLocalizedDateTime(style);
// or DateTimeFormatter.ofLocalizedDateTime(style1, style2)
/** 以上格式器都会使用当前的locale。
* 为了使用不同的locale,
* 需要使用withLocale方法:
*/
DateTimeFormatter dateFormatter =
DateTimeFormatter.ofLocalizedDate(style).withLocale(locale);
7.4 排序和规范化
/** 获得locale敏感的比较器,
* 可以调用静态的Collator.getInstance方法:
*/
Collator coll = Collator.getInstance(locale);
words.sort(coll); // Collator implements Comparator<Object>
7.5 消息格式化
- Java类库中有一个用来对包含变量部分的文本进行格式化的MessageFormat类,它的格式化方式与用printf方法进行格式化很类似,但是它支持locale,并且可以对数字和日期进行格式化。
7.5.1 格式化数字和日期
- 一个典型的消息格式化字符串:
“On {2}, a {0} destroyed {1} houses and caused {3} of damage.”
/** 括号中的数字是占位符,
* 可以用实际的名字和值来替换它们。
* 使用静态方法MessageFormat.format
* 可以用实际的值来替换这些占位符。
*/
String msg =
MessageFormat.format("On {2}, a {0} destroyed {1} houses and caused {3} of damage.",
"hurricane", 99, new GregorianCalendar(1999, 0, 1).getTime(), 10.0E8);
/** 结果是下面的字符串:
* On 1/1/99 12:00 AM, a hurricane destroyed 99 houses and caused 100,000,000 of damage.
*/
/** 还可以为占位符提供可选的格式。
*/
String msg =
MessageFormat.format("On {2,date,long}, a {0} destroyed {1} houses and caused {3,number,currency} of damage.",
"hurricane", 99, new GregorianCalendar(1999, 0, 1).getTime(), 10.0E8);
/** 结果是下面的字符串:
* On January 1, 1999 12:00 AM, a hurricane destroyed 99 houses and caused $100,000,000 of damage.
*/
一般来说,占位符索引后面可以跟一个类型(type)和一个风格(style),它们之间用逗号隔开。
类型可以是:
number
time
date
choice
如果类型是number,那么风格可以是:
integer
currency
percent
如果类型是time或date,那么风格可以是:
short
medium
long
full
7.5.2 选择格式
- 一个选择格式是由一个序列对构成的,每一个对包括:
一个下限(lower limit)。
一个格式字符串(format string)。
7.6 文本输入和输出
7.6.1 文本文件
/** 若知道遗留文件所希望使用的字符编码机制,
* 可在读写文本文件时指定它:
*/
var out = new PrintWriter(filename, "Windows-1252");
/** 获得可用的最佳编码机制,
* 可以通过下面的调用来获得“平台的编码机制”:
*/
Charset platformEncoding = Charset.defaultCharset();
7.6.2 行结束符
- 这不是locale的问题,而是平台的问题。在Windows中,文本文件希望在每行末尾使用\r\n,而基于UNIX的系统只需要一个\n字符。
/** 与在字符串中使用\n不同,
* 可以使用printf和%n格式说明符来产生平台相关的行结束符。
*/
out.printf("Hello%nWorld%n");
/** 在Windows上产生
* Hello\r\nWorld\r\n
* ***
* 在其他所有平台上产生
* Hello\nWorld\n
*/
7.6.3 控制台
- 若程序是通过System.in/System.out或System.console()与用户交互的,那么就不得不面对控制台使用的字符编码机制与Charset.defaultCharset()报告的平台编码机制有差异的可能性。
7.6.4 日志文件
- 当来自java.util.logging库的日志消息被发送到控制台时,它们会用控制台的编码机制来书写。
7.7 资源包
- 当本地化一个应用时,可能会有大量的消息字符串、按钮标签和其他的东西需要被翻译。为了灵活地完成这项任务,一般在外部定义消息字符串,这些消息字符串通常被称为资源(resource)。
7.7.1 定位资源包
- 一般来说,使用 baseName_language_country 来命名所有和国家相关的资源,使用 baseName_language 来命名所有和语言相关的资源。
// 加载一个包:
ResourceBundle currentResources = ReourceBundle.getBundle(baseName, currentLocale);
7.7.2 属性文件
- 对字符串进行国际化是很直接的,可以把所有的字符串放到一个属性文件中,比如 MyProgramStrings.properties,这是一个每行存放一个键-值对的文本文件。
computeButton=Rechnen
colorName=black
defaultPaperSize=210*297
/** 可以像上一节描述的那样命名属性文件,
* 例如,
* MyProgramStrings.properties
* MyProgramStrings_en.properties
* MyProgramStrings_de_DE.properties
*/
ResourceBundle currentResources = ReourceBundle.getBundle("MyProgramStrings", locale);
/** 要查找一个集体的字符串,
* 可以调用
*/
String computeButtonLabel = bundle.getString("computeButton");
7.7.3 包类
- 为了提供字符串以外的资源,需要定义类,它必须扩展自ResourceBundle类。应该使用标准命名规则来命名类,比如:
MyProgramStrings.java
MyProgramStrings_en.java
MyProgramStrings_de_DE.java
第8章 脚本、编译与注解处理
Java平台的脚本机制
标准注解
编译器API
源码级注解处理
使用注解
字节码工程
注解语法
8.1 Java平台的脚本机制
- 脚本语言是一种通过在运行时解释程序文本,从而避免使用通常的编辑/编译/链接/运行循环的语言。
- 脚本语言有许多优势:
- 便于快速变更,鼓励不断实验。
- 可以修改运行着的程序的行为。
- 支持程序用户的定制化。
8.1.1 获取脚本引擎
- 脚本引擎是一个可以执行用某种特定语言编写的脚本的类库。
- 脚本引擎工厂的属性:
| 引擎 | 名字 | MIME类型 | 文件扩展 |
|---|---|---|---|
| Nashorn(包含在JDK中) | nashorn, Nashorn, js, JS, JavaScript, javascript, ECMAScript, ecmascript |
application/javascript, application/ecmascript, text/javascript, text/ecmascript |
js |
| Groovy | groovy | 无 | groovy |
| Renjin | Renjin | text/x-R | R, r, S, s |
/** 知道所需要的引擎,
* 可以直接通过名字、MIME类型或文件扩展来请求它:
*/
ScriptEngine engine = manager.getEngineByName("nashorn");
8.1.2 脚本计算与绑定
/** 一旦拥有了引擎,
* 就可以通过下面的调用来直接调用脚本:
*/
Object result = engine.eval(scriptString);
/** 如果脚本存储在文件中,
* 那么需要先打开一个Reader,
* 然后调用:
*/
Object result = engine.eval(reader);
/** 可以在同一个引擎上调用多个脚本。
* 如果一个脚本定义了变量、函数或类,
* 那么大多数引擎都会保留这些定义,
* 以供将来使用。
*/
engine.eval("n = 1728");
Object result = engine.eval("n + 1"); // 将返回 1729
要想知道在多个线程中并发执行脚本是否安全,可以调用
Object param = factory.getParameter(“THREADING”);
其返回值是下列值之一:
null:并发执行不安全
“MULTITHREADED”:并发执行安全。一个线程的执行效果对另外的线程有可能是可视的。
“THREAD-ISOLATED”:除了 “MULTITHREADED”,还会为每个线程维护不同的变量绑定。
“STATELESS”:除了 “THREAD-ISOLATED”,脚本还不会改变变量绑定。
8.1.3 重定向输入和输出
- 可以通过调用脚本上下文的setReader和setWriter方法来重定向脚本的标准输入和输出。
/** 任何用JavaScript的print和println函数产生的输出都会被发送到writer。
*/
var writer = new StringWriter();
engine.getContext().setWriter(new PrintWriter(writer, true));
/** setReader和setWriter方法只会影响脚本引擎的标准输入和输出源。
* 执行下面的JavaScript代码,
* 只有第一个输出会被重定向。
*/
println("Hello");
java.lang.System.out.println("World");
8.1.4 调用脚本的函数和方法
/** 要调用一个函数,
* 需要用函数名来调用invokeFunction方法,
* 函数名后面是函数的参数:
*/
// Define greet function in JavaScript
engine.eval("functionn greet(how, whom) { return how + ', ' + whom + '!' }");
// Call the function with arguments "Hello", "World"
result = ((Invocable) engine).invokeFunction("greet", "Hello", "World");
/** 如果脚本语言是面向对象的,
* 那就可以调用invokeMethod:
*/
// Define Greeter class in JavaScript
engine.eval("function Greeter(how) { this.how = how }");
engine.eval("Greeter.prototype.welcome = "
+ " function(whom) { return this.how + ', ' + whom + '!'}");
// Construct an instance
Object yo = engine.eval("new Greeter('Yo')");
// Call the welcome method on the instance
result = ((Invocable) engine).invokeMethod(yo, "welcome", "World");
- 使用脚本实现一个Java接口,然后就可以用Java方法调用的语法来调用脚本函数。
// 接口
public interface Greeter {
String welcome(String whom);
}
/** 如果在Nashorn中定义了具有相同名字的函数,
* 那么可通过这个接口来调用它:
*/
// Define welcome function in JavaScript
engine.eval("function welcome(whom) { return 'Hello, ' + whom + '!'}");
// Get a Java object and call a Java method
Greeter g = ((Invocable) engine).getInterface(Greeter.class);
result = g.welcome("World");
/** 在面对对象的脚本语言中,
* 可以通过相匹配的Java接口来访问一个脚本类。
* 例如,
* 使用Java的语法来调用JavaScript的SimpleGreeter类:
*/
Greeter g = ((Invocable) engine).getInterface(yo, Greeter.class);
result = g.welcome("World");
8.1.5 编译脚本
- 某些脚本引擎处于对执行效率的考虑,可以将脚本代码编译为某种中间格式。
/** 编译和计算包含在脚本文件中的代码:
*/
var reader = new FileReader("myscript.js");
CompiledScript script = null;
if (engine implements Compilable)
script = ((Compilable) engine).compile(reader);
/** 下面的代码会在编译成功的情况下执行编译后的脚本,
* 如果引擎不支持编译,
* 则执行原始的脚本。
*/
if (script != null)
script.eval();
else
engine.eval(reader);
8.2 编译器API
8.2.1 调用编译器
/** 调用编译器非常简单,
* 下面是一个示范调用:
*/
JavaCompiler compiler = ToolProvider.getSystemJavaCompiler();
OutputStream outStream = ...;
OutputStream errStream = ...;
int result = compiler.run(null, outStream, errStream,
"-sourcepath", "src", "Test.java");
// 返回值为0表示编译成功
8.2.2 发起编译任务
- 可以通过使用CompilationTask对象来对编译过程进行更多的控制。
/** 要想获取CompilationTask对象,
* 需要以前一节中描述的compiler对象开始,
* 然后按照下面的方式调用:
*/
JavaCompiler.CompilationTask task = compiler.getTask(
errorWriter, // Uses System.err if null
fileManager, // Uses the standard file manager if null
diagnostics, // Uses System.err if null
options, // null if no options
classes, // For annotation processing; null if none
sources);
/** 最后三个参数是Iterable的实例。
* 例如,选定序列可以像下面这样指定:
*/
Iterable<String> options = List.of("-d", "bin");
/** sources参数是JavaFileObject实例的Iterable。
* 如果想要编译磁盘文件,
* 需要获取一个StandardJavaFileManager对象,
* 并调用其getJavaFileObject方法:
*/
StandardJavaFileManager fileManager = compiler.getStandardFileManager(null, null, null);
Iterable<JavaFileObject> sources
= fileManager.getJavaFileObjectsFromStrings(List.of("File1.java", "File2.java"));
JavaCompiler.CompilationTask task = compiler.getTask(
null, null, null, options, null, sources);
8.2.3 捕获诊断消息
- 为了监听错误消息,需要安装一个DiagnosticListener。这个监听器在编译器报告警告或错误消息时会收到一个Diagnostic对象。
/** DiagnosticCollector类实现了这个接口,
* 它将收集所有的诊断信息,
* 可以在编译完成之后遍历这些信息。
*/
DiagnosticCollector<JavaFileObject> collector = new DiagnosticCollector<>();
compiler.getTask(null, fileManager, collector, null, null, sources).call();
for (Diagnostic<? extends JavaFileObject> d : collector.getDiagnostics()) {
System.out.printl(d);
}
/** 还可以在标准的文件管理器上安装一个DiagnosticListener对象,
* 这样就可以捕获到有关文件缺失的消息:
*/
StandardJavaFileManager fileManager
= compiler.getStandardFileManager(diagnostics, null, null);
8.2.4 从内存中读取源文件
/** 若动态地生成了源代码,
* 那么就可以从内存中获取它来进行编译,
* 而无须在磁盘上保存文件。
*/
public class StringSource extends SimpleJavaFileObject {
private String code;
StringSource(String name, String code) {
super(URI.create("string:///" + name.repalce('.','/') + ".java", Kind.SOURCE);
this.code = code;
}
public CharSequence getCharContent(boolean ignoreEncodingErrors) {
return code;
}
}
/** 然后,生成类的代码,
* 并提交给编译器一个StringSource对象的列表:
*/
List<StringSource> sources = List.of(
new StringSource(className1, class1CodeString), ...);
task = compiler.getTask(null, fileManager, diagnostics, null, null, sources);
8.2.5 将字节码写出到内存中
- 如果动态地编译类,那么就无须将类文件写出到硬盘上。可以将它们存储在内存中,并立即加载它们。
8.3 使用注解
- 注解是那些插入到源代码中使用其他工具可以对其进行处理的标签。
- 注解可能的用法:
附属文件的自动生成,例如部署描述符或者bean信息类。
测试、日志、事务语义等代码的自动生成。
8.3.1 注解简介
- 在Java中,注解是当作一个修饰符来使用的,它被置于被注解项之前,中间没有分号。
// 例如:
public class MyClass {
...
@Test public void checkRandomInsertions()
}
8.4 注解语法
8.4.1 注解接口
- 注解是由注解接口来定义的:
modifiers @interface AnnotationName {
elementDeclaration1
elementDeclaration2
...
}
/** 每个元素声明都具有下面这种形式:
*/
type elementName(); // or type elementName() default value;
/** 例如,下面这个注解具有两个元素:
* assignedTo和severity。
*/
public @interface BugReport {
String assignedTo() default "[none]";
int severity();
}
- 注解元素的类型为下列之一:
基本类型(int、short、long、type、char、double、float或者boolean)。
String。
Class(具有一个可选的类型参数,例如Class<? extends MyClass)。
enum类型。
注解类型。
由以上所述类型组成的数组(由数组组成的数组不是合法的元素类型)。
8.4.2 注解
/** 每个注解都具有下面这种格式:
*/
@AnnotationName(elementName1=value1, elementName2=value2, ...)
/** 例如,
*/
@BugReport(assignedTo="Harry", severity=10)
/** 元素的顺序无关紧要,
* 下面这个注解与前面那个一样。
*/
@BugReport(severity=10, assignedTo="Harry")
/** 如果某个元素的值并未指定,那么就使用声明的默认值。
* 例如,下面这个注解中,
* assignedTo的值是字符串 "[none]"。
*/
@BugReport(severity=10)
/** 如果没有指定元素,
* 要么是因为注解中没有任何元素,
* 要么是因为所有元素都使用默认值。
*/
@BugReport
// 称为 标记注解,等同于
@BugReport(assignedTo="[none]", severity=0)
/** 单值注解
* 如果一个元素具有特殊的名字value,
* 并且没有指定其他元素,
* 那么就可以忽略掉这个元素名以及等号。
*/
public @interface ActionListenerFor {
String value();
}
/** 那么,
* 可以将注解书写为以下形式:
*/
@ActionListenerFor("yellowButton")
8.4.3 注解各类说明
/** 1. 对于类和接口,
* 需要将注解放置在class和interface关键词的前面:
*/
@Entity public class User {...}
/** 2. 对于变量,
* 需要将它们放置在类型的前面:
*/
@SuppressWarnings("unchecked") List<User> users = ...;
public User getUser(@Param("id") String userId)
/** 3. 对于泛化类或方法中的类型参数:
*/
public class Cache<@Immutable V> {...}
/** 4. 包是在文件package-info.java中注解的,
* 该文件只包含以注解先导的包语句。
*/
/**
Package-level Javadoc
*/
@GPL(version="3")
package com.horstnann.corejava;
import org.gnu.GPL
8.4.4 注解类型用法
- 声明注解提供了正在被声明的项的相关信息。
public User getUser(@NonNull String userId)
// 断言userId参数不为空
List<@NonNull String>
// 断言其中所有字符串不为空
- 类型用法注解可以出现在下面的位置:
- 与泛化类型参数一起使用:List<@NonNull String>, Comparator.<@NonNull String> reverseOrder()>。
- 数组中的任何位置:@NonNull String[][] words(words[i][j]不为null),String @NonNull [][] words(words不为null),String[] @NonNull [] words(words[i]不为null)。
- 与超类和实现接口一起使用:class Warning extends @Localized Message。
- 与构造器调用一起使用:new @Localized String(…)。
- 与强制转型和instanceof检查一起使用:(@Localized String) text, if (text instanceof @Localized String)。
- 与异常规约一起使用:public String read() throws @Localized IOException。
- 与通配符和类型边界一起使用:List<@Localized ? extends Message>,List<? extends @Localized Message>。
- 与方法和构造器引用一起使用:@Localized Message::getText。
8.4.5 注解this
/** 假设想要将参数注解为在方法中不会被修改。
*/
public class Point {
public boolean equals(@ReadOnly Object other) { ... }
}
/** 处理这个注解的工具在看到下面的调用时,
* p.equals(q);
* 就会推理出q没有被修改过。
* 当该方法被调用时,
* this变量是绑定到p的。
* 但是this从来都没有被声明过,
* 因此无法注解它。
*/
/** 实际上,
* 可以用一种很少使用的语法变体来声明它,
* 这样就可以添加注解了。
*/
public class Point {
public boolean equals(@ReadOnly Point this, @ReadOnly Object other) { ... }
}
// 第一个参数被称为接收器参数,它必须被命名为this,其类型为要构建的类。
/** 传递给内部类构造器的是另一个不同的隐藏参数,
* 即对其外围类对象的引用。
* 可以让这个参数显示化。
* 这个参数的名字必须像引用它时那样,叫做EnclosingClass.this,其类型为外围类
*/
public class Sequence {
private int from;
private int to;
class Iterator implements java.util.Iterator<Integer> {
private int current;
public Iterator(@ReadOnly Sequence Sequence.this) {
this.current = Sequence.this.from;
}
...
}
...
}
8.5 标准注解
| 注解接口 | 应用场合 | 目的 |
|---|---|---|
| @Deprecated | 全部 | 将项标记为过时的 |
| @SafeVarargs | 方法和构造器 | 断言varargs参数可安全使用 |
| @Override | 方法 | 检查该方法是否覆盖了某一个超类方法 |
| @FunctionalInterface | 接口 | 将接口标记为只有一个抽象方法的函数式接口 |
| @PostConstruct PreDestroy | 方法 | 被标记的方法应该在构造之后或移除之前立即被调用 |
| @Resource | 类、接口、方法、域 | 在类或接口上:标记为在其他地方要用到的资源。在方法或域上:为“注入”而标记 |
| @Resources | 类、接口 | 一个资源数组 |
| @Generated | 全部 | |
| @Target | 注解 | 指明可以应用这个注解的那些项 |
| @Retention | 注解 | 指明这个注解可以保留多久 |
| @Documented | 注解 | 指明这个注解应该包含在注解项的文档中 |
| @Inherited | 注解 | 指明当这个注解应用于一个类的时候,能够自动被它的子类继承 |
| @Repeatable | 注解 | 指明这个注解可以在同一个项上应用多次 |
第9章 Java平台模块系统
模块的概念
自动模块
对模块命名
不具名模块
…
9.1 模块的概念
- 一个Java平台模块包括:
- 一个包集合。
- 可选地包含资源文件和像本地库这样的其他文件。
- 一个有关模块中可访问的包的列表。
- 一个有关这个模块依赖的所有其他模块的列表。
- Java平台模块系统的两个优点:
- 强封装性:可以控制哪些包是可访问的,并且无须操心去维护那些不想开发给公众去访问的代码。
- 可靠的配置:可以避免诸如类重复或丢失这类常见的类路径问题。
9.2 对模块命名
- 模块名是由字母、数字、下划线和句点构成的。
- 模块之间没有任何的层次关系。
例如,模块com.horstmann 和 模块com.horstmann.corejava,就模块系统而言,它们是无关的。
9.3 模块化的“Hello World!”程序
- 首先将这个类放到一个包中,“不具名的”包是不能包含在模块中的。
package com.horstmann.hello;
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello, Modular World!");
}
}
- 然后创建包含这个包的v2ch09.hellomod模块,需要添加一个模块声明,可以将其置于名为module-info.java的文件中,该文件位于基目录中(即,与包含com目录的目录相同)。
module v2ch09.hellomod {
}
9.4 对模块的需求
package com.horstmann.hello;
import javax.swing.JOptionPane;
public class HelloWorld {
public static void main(String[] args) {
JOptionPane.showMessageDialog(null,"Hello, Modular World!");
}
}
- 使用了javax.swing包,其包含在java.desktop模块中。所以需要声明它依赖于这个模块:
module v2ch09.hellomod {
requires java.desktop;
}
第10章 安全
类加载器
数字签名
安全管理器与访问权限
加密
用户认证
- Java技术提供了三种确保安全的机制:
- 语言设计特性(对数组的边界进行检查,无不受检查的类型转换,无指针算法等)。
- 访问控制机制,用于控制代码能够执行的操作(比如文件访问,网络访问等)。
- 代码签名,利用该特性,代码的作者就能够用标准的加密算法来认证Java代码。这样,该代码的使用者就能够准确地知道谁创建了该代码,以及代码签名后是否被修改过。
10.1 类加载器
- Java编译器会为虚拟机转换源指令。虚拟机代码存储在以 .class 为扩展名的类文件中,每个类文件都包含某个类或者接口的定义和代码实现。
10.1.1 类加载过程
- 虚拟机只加载程序执行时所需要的类文件。例如,假设程序从 MyProgram.class 开始运行,下面是虚拟机执行的步骤:
- 虚拟机有一个用于加载类文件的机制,例如,从磁盘上读取文件或者请求Web上的文件,它使用该机制来加载 MyProgram 类文件中的内容。
- 如果 MyProgram 类用于类型为另一个类的域,或者是拥有超类,那么这些类文件也会被加载。(加载某个类所依赖的所有类的过程称为类的解析。)
- 接着,虚拟机执行 Myprogram 中的 main 方法(它是静态的,无须创建类的实例)。
- 如果 main 方法或者 main 调用的方法要用到更多的类,那么就下来就会加载这些类。
- 类加载机制并非只使用单个的类加载器。每个Java程序至少拥有三个类加载器:
引导类加载器
平台类加载器
系统类加载器(有时也称为应用类加载器)
10.1.2 类加载器的层次结构
- 类加载器有一种父/子关系。除了引导类加载器外,每个类加载器都有一个父类加载器。
- 类加载器会为它的父类加载器提供一个机会,以便加载任何给定的类,并且只有在其父类加载器加载失败时,它才会加载该给定类。
10.1.3 将类加载器用作命名空间
- 在同一个虚拟机中,可以有两个类,它们的类名和包名都是相同的。
因为每个类都是由单独的类加载器加载的,所以这些类可以彻底地区分开而不会产生任何冲突。
10.1.4 编写自己的类加载器
- 编写自己的用于特殊目的的类加载器,使得在向虚拟机传递字节码之前执行定制的检查。
10.1.5 字节码校验
- 当类加载器将新加载的Java平台类的字节码传递给虚拟机时,这些字节码首先要接受校验器(verifier)的校验。
- 校验器执行的一些检查:
变量要在使用之前进行初始化。
方法调用与对象引用类型之间要匹配。
访问私有数据和方法的规则没有被违反。
对本地变量的访问都落在运行时堆栈内。
运行时堆栈没有溢出。
10.2 安全管理器与访问权限
- 一旦某个类被加载到虚拟机中,并由检验器检查过之后,Java平台的第二种安全机制就会启动,这个机制就是安全管理器。
10.2.1 权限检查
- 安全管理器是一个负责控制具体操作是否被允许执行的类。
- 安全管理器负责检查的操作包括以下内容:
创建一个新的类加载器
退出虚拟机
使用反射访问另一个类的成员
访问本地文件
打开socket连接
启动打印作业
访问系统剪贴板
访问AWT时间队列
打开一个顶层窗口
10.2.2 Java平台安全性
- 从Java 1.2开始,Java平台拥有了更灵活的安全机制,它的策略建立了代码来源和访问权限集之间的映射关系。
- 一个安全策略:
- 代码来源(code source)是由一个代码位置和一个证书集指定的。
- 权限(permission)是指由安全管理器负责检查的任何属性。
10.2.3 安全策略文件
- 策略管理器要读取相应的策略文件,这些文件包含了将代码来源映射为权限的指令。
10.3 用户认证
10.3.1 JAAS框架
- Java认证和授权服务(JAAS,Java Authentication and Authorization Service)包含两部分:“认证”部分主要负责确定程序使用者的身份,而“授权”将各个用于映射到相应的权限。
- JAAS是一个可插拔的APII,可以将Java应用程序与实现认证的特定技术分离开来。
10.4 数字签名
10.4.1 消息摘要
- 消息摘要(message digest)是数据块的数字指纹。
- 消息摘要具有两个基本属性:
- 如果数据的1位或者几位改变了,那么消息摘要也将改变。
- 拥有给定消息的伪造者无法创建与原消息具有相同摘要的假消息。
10.4.2 消息签名
- 数字签名的工作原理是公共密钥加密技术。
- 公共密钥加密技术是基于公共密钥和私有密钥这两个基本概念的。
假设Alice想要给Bob发送一个消息,Bob想知道该消息是否来自Alice,而不是冒名顶替者。Alice写好了消息,并且用她的私有密钥对该消息摘要签名。Bob得到了她的公共密钥的拷贝,然后Bob用公共密钥对该签名进行校验。如果通过了校验,则Bob可以确定以下两个事实:
- 原始消息没有被篡改过。
- 该消息是由Alice签名的,她是私有密钥的持有者,该私有密钥就是与Bob用于校验的公共密钥相匹配的密钥。
10.5 加密
- 数字签名只不过负责检验信息有没有被篡改过。相比之下,信息被加密后,是不可见的,只能用匹配的密钥进行解密。
第11章 高级Swing和图形化编程
- 略
第12章 本地方法
从Java程序中调用C函数
调用Java方法
数值参数与返回值
访问数组元素
…
- 原则上说,“100%纯Java”的解决方案是非常好的,但有时也会想要编写或使用其他语言的代码(通常称为本地代码)。
- 只有在必需的时候才使用本地代码。特别是以下三种情况:
- 应用需要访问的系统特性和设备通过Java平台是无法实现的。
- 已经有了大量的测试过和调试过的另一种语言的代码,并且知道如何将其导出到所有目标平台上。
- 通过基准测试,发现所编写的Java代码比用其他语言编写的等价代码要慢得多。
12.1 从Java程序中调用C函数
- Java编程语言使用关键字 native 表示本地方法。关键字 native 提醒编译器该方法将在外部定义。
- 对本地代码的处理:

Comments